

The Trap of the Green Debug Screen: Why Salesforce Flow Testing Needs Node-Level Trace
Short answer: Salesforce Flow testing should prove more than “the Flow ran.” It should show the trigger, runtime context, execution path, node-level values, sub-flow activity, and final business outcome so teams can diagnose what happened instead of guessing from a green debug screen.
The Flow ran. The record saved. The debug screen looked green.
Then the business process still broke.
That is the trap.
Salesforce Flow failures rarely announce themselves with a dramatic error. They show up as missing contacts, skipped approvals, wrong inventory states, broken case handoffs, misrouted orders, and records that look fine until someone downstream realizes the process did not actually complete.
By then, QA is already in the worst possible position: trying to reconstruct what happened from a stale user story, a blank test-case template, a partial debug run, and a release manager asking whether this is safe to ship.
The stronger starting point looks at two things:
Business intent: what should happen.
Live implementation: what is actually shaping the outcome right now.
Put those together, and Salesforce Flow testing gets sharper immediately. You stop asking only, “Did this Flow execute?” and start asking the question that actually matters: “What path did it take, what values moved through it, and did the business outcome hold?”

A Green Run Is Not Evidence
Salesforce’s debug tools are useful. They help admins and QA teams inspect logic, test scenarios, and catch obvious mistakes earlier.
But a successful debug run is not the same thing as a tested Flow.
It does not prove the Flow behaved the same way in the real runtime context. It does not prove the right record values were present when the decision node evaluated. It does not prove the correct sub-flow was called, the right record type was used, or the expected business result happened outside the controlled debug session.
Teams run into this constantly. The Flow works in debug, then behaves differently when triggered from a real page, a scheduled job, an API call, or a real user context. A branch that should have fired never did. A field looked populated in the log but did not persist on the record. A record was created, but with the wrong values.
The problem is usually not that nobody tested.
The problem is that the team stopped too early and accepted “it ran” as proof.
It is not.
Salesforce Flows Are Business Logic With a Visual Editor
Low-code does not mean low-risk.
That belief survives because Flow looks approachable. It is visual. It is easier to assemble than code. It feels closer to configuration than engineering.
But once a Flow drives order management, approvals, inventory updates, routing, customer communications, case movement, or commerce exceptions, the visual editor stops being the point.
The Flow is business logic.
It branches. It loops. It calls sub-flows. It depends on data shape, permissions, trigger order, related records, validation rules, page context, and surrounding automation. In a serious Salesforce org, the canvas is only one part of the truth.
That is why treating Flows like lightweight admin assets is risky. They need regression thinking. They need repeatable evidence. They need tests designed around how the system actually behaves, not how clean the diagram looks.
What Public Evidence Tells Us About Flow Testing Gaps
Salesforce has been improving Flow testing in meaningful ways. Its own documentation says automated Flow testing supports record-triggered, autolaunched, and Data Cloud-triggered flows, and Salesforce recommends testing flows before activation. Trailhead also shows why context matters: admins can debug flows as another user because permissions and sharing can change the result.
That is progress.
But it does not erase the deeper testing problem: debug evidence is still easy to misunderstand, and runtime behavior can differ from the neat scenario someone expected.
Community discussions show this pain clearly. In one Salesforce Reddit thread, a user described a Flow that worked perfectly in debug but did nothing when activated. The likely issue was not the decision logic; commenters pointed out that assignment alone does not persist changes without the right update action. In another thread, a scheduled Flow appeared to run correctly in debug but updated no records overnight, leading the discussion toward timing, filters, running-user logs, and schedule behavior.
Salesforce’s own UI automation guidance adds another layer. Lightning hides implementation identifiers and uses Shadow DOM, which makes traditional selector-based UI tests brittle. Salesforce notes that DOM changes can force test maintenance from release to release.
The pattern is hard to miss: Salesforce testing failures often live in the gap between what the test appeared to prove and what the system actually did.
That gap is where node-level trace becomes important.
The Hardest Flow Bug Is Usually a Value You Cannot See
Most Flow bugs are not mysterious because the logic is impossible to read.
They are mysterious because the decisive value is hidden at the moment it matters.
A missing recordId.
A null variable.
A record type mismatch.
A permission difference.
A lookup that did not resolve.
A field that exists in one environment and not another.
A condition that evaluated differently because the input record was not as complete as everyone assumed.
This is where traditional Flow testing falls short. Teams look at the route and miss the reason.
A Flow diagram shows the path.
Node values show the reason.
That distinction is the difference between a bug report and a diagnosis.
If a decision node took the wrong branch, QA needs to see the value that drove the decision. If a Create Records element produced the wrong contact, the team needs the exact values used at that node. If a sub-flow did not fire, the question is not only whether it was available. The question is whether it received the right input at the right moment.
Without that visibility, you end up guessing what happened, which turns debugging into storytelling. People infer the cause from scattered artifacts, rerun scenarios, compare notes, and burn hours getting back to something the original test run should have made obvious.
Node-level tracing changes that. It turns a vague failure into a diagnosis.

Test Data Is the Hidden Contract Behind Every Flow
A Flow test is only as trustworthy as the data that triggered it.
This is where blank QA templates become actively misleading. A template can suggest structure, but it cannot tell you what the automation really depends on.
In practice, Flows are sensitive to required fields, record types, validation rules, lookup relationships, permissions, profile context, timing, and surrounding automation. Those are not edge details. They are the contract.
In a Salesforce commerce app, you feel this fast. A return Flow may only move when the original order has the right fulfillment state. An inventory Flow may only branch correctly if warehouse mapping, item availability, and channel metadata all line up. An order exception Flow may look healthy in isolation while failing in the real UI path because runtime context passed different values than QA expected.
Bad test data can make a correct Flow look broken.
Worse, it can make a broken Flow look correct.
That is why the best Flow test design starts from business intent plus current implementation. The intent tells you the outcome. The implementation tells you the values, triggers, permissions, and dependencies that decide whether that outcome happens.
One without the other is incomplete.
Natural-Language Scenarios: Making Flow Test Cases Reviewable Across Teams
One quiet problem in Salesforce QA is that admins, QA engineers, developers, and business stakeholders often describe the same scenario in different languages.
The business talks in outcomes.
QA talks in assertions.
Developers talk in execution.
Admins talk in fields, objects, and configuration.
Important context gets lost in the translation.
Natural-language test design helps when it stays precise. The advantage is not that it makes testing informal. The advantage is that it makes the scenario reviewable across roles while still producing executable checks.
A vague test case says:
“Verify account creation Flow works.”
A useful scenario says:
“When a new Account is created with record type Partner and region West, verify the onboarding Flow creates the correct contact task, assigns it to the partner operations queue, skips the enterprise approval branch, and records the node values that drove each decision.”
That is reviewable. It is also testable.
The best Flow test cases are not the ones that look exhaustive in a spreadsheet. They are the ones that preserve intent clearly enough that a Salesforce admin, QA lead, and release manager can all understand what is being tested and why it matters.
From “It Ran” to “Here Is the Trace”
The most useful Flow artifact is not a green indicator.
It is a trace the team can work from.
That means showing the exact path followed for the scenario, not just the abstract diagram. It means linearizing the execution so reviewers can see what happened step by step. It means capturing node-level values, timestamps, sub-flow activity, and record operations in a way that helps QA, admins, and developers debug from the same evidence.
This is where Flow testing becomes more mature.
Once the output changes from “passed” to “here is the path, here are the values, here is where it diverged,” the team conversation changes. Root cause gets faster. Review gets clearer. Release confidence improves because people are no longer guessing whether the automation worked.
They can see why it worked.
Or exactly why it failed.
At TestZeus, this is the shift we see across Salesforce testing more broadly: away from script maintenance and toward agent supervision with traceable evidence. In Flow testing specifically, TestZeus connects natural-language scenarios to execution traces so teams can move from “the test ran” to “the business process was proven, and here is the evidence.”
Not more noise.
Better evidence.
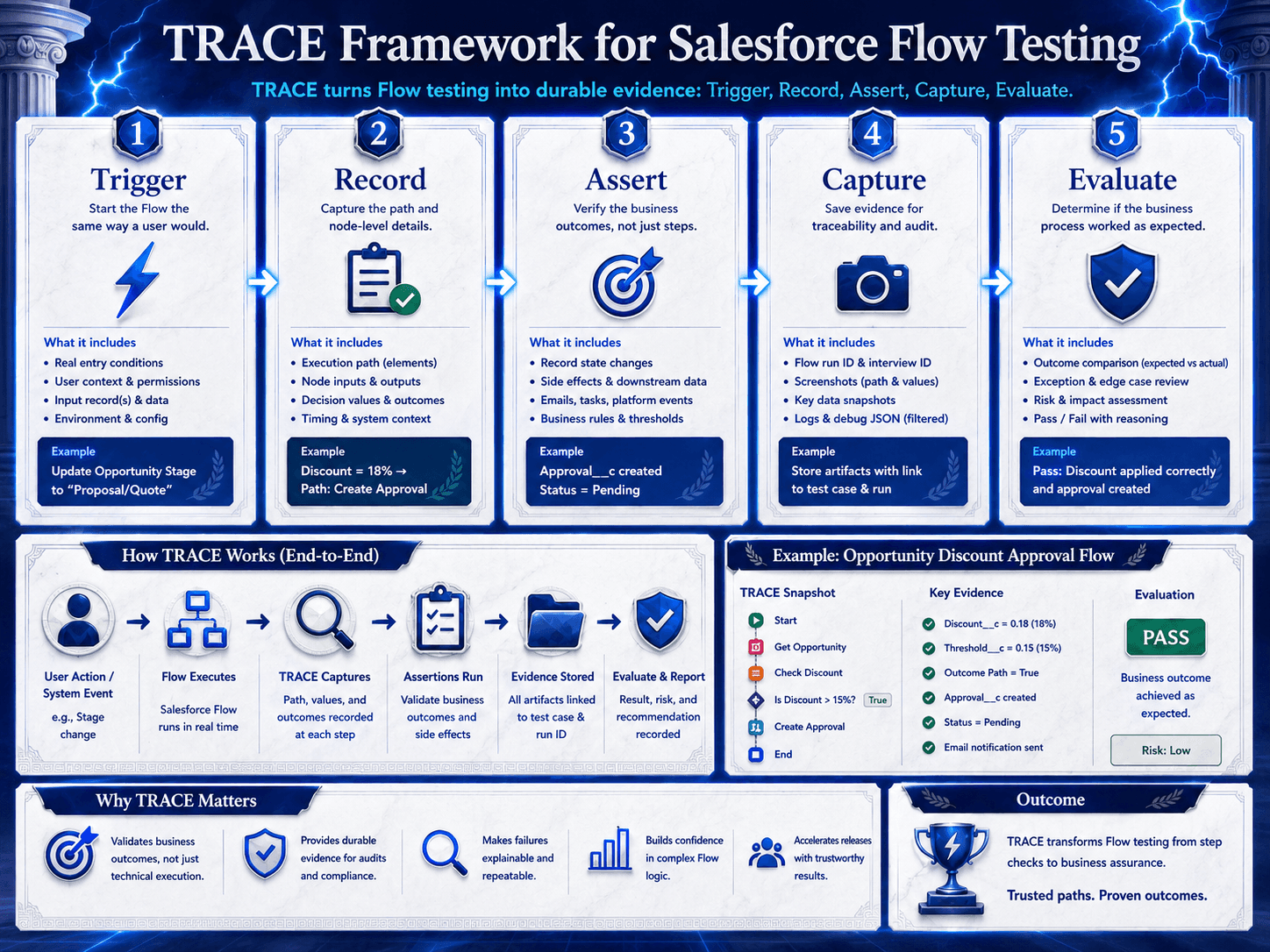
The TRACE Framework for Salesforce Flow Testing
If teams want a simple way to raise the quality of Flow QA, use the TRACE framework.
Step | What It Means | What To Verify |
T: Trigger with reliable test data | Create the records, fields, record types, permissions, and runtime context needed to exercise the Flow meaningfully. | Did the test start from realistic data and the right user/context? |
R: Record the execution path | Capture the branches, loops, nodes, and sub-flows the scenario actually touched. | Can the team see the path the Flow really followed? |
A: Assert node-level outputs | Check values at decisions, updates, creates, assignments, and handoffs. | Can the team prove why each important node behaved the way it did? |
C: Capture evidence with timestamps | Preserve the path, values, timing, and artifacts for review. | Can QA, admins, and developers debug from the same source of truth? |
E: Evaluate and iterate | Use the trace to explain failures, improve the Flow, strengthen data, and rerun. | Did the test produce learning, not just pass/fail status? |
The point of TRACE is simple: stop treating the test as a pass-fail event and start treating it as evidence.
The Standard Has to Get Higher
The stale belief to retire is this:
If the Flow debug run succeeds, the Flow is tested.
It is not.
A Flow should not be trusted because it looked green once. It should be trusted because the team can prove the trigger, path, values, and outcome.
That is true in any Salesforce org. It becomes unavoidable in commerce apps, operational workflows, and release environments where Flow logic carries real business consequences.
If QA is testing order management, inventory movement, approvals, customer onboarding, or case escalation, a blank test-case template and a maybe-current user story are weak starting points. The stronger standard is business intent plus current implementation, backed by traceable runtime evidence.
That is what separates test theater from release confidence.
If you cannot trace the node, you cannot trust the Flow.
Practical Takeaways
Stop treating Debug as the finish line. Use it as an inspection tool, not proof of release readiness.
Design Flow tests around business outcomes and runtime behavior, not only the visual canvas.
Capture node-level values for decisions, creates, updates, sub-flows, and handoffs.
Treat test data as part of the Flow contract. Record types, permissions, lookups, and related records can change the result.
Make scenarios reviewable in natural language, then back them with executable evidence.
Use TRACE as a practical standard for higher-confidence Salesforce Flow testing.
FAQ
What is Salesforce Flow testing?
Salesforce Flow testing verifies that a Flow triggers under the right conditions, follows the expected path, uses the correct data, and produces the intended business outcome. Strong Flow testing also captures evidence about the execution path and values used inside the Flow.
Why is Salesforce Flow testing harder than clicking Debug?
Debugging shows useful information, but real Flow behavior can depend on runtime context, permissions, record relationships, trigger timing, validation rules, and surrounding automation. A debug run can help without fully proving production-like behavior.
What are node-level values in Salesforce Flow debugging?
Node-level values are the actual inputs, outputs, variables, and record values present at each Flow element. They help teams understand why a decision branch executed, why a record changed, or why a sub-flow did not behave as expected.
Why does test data matter in Salesforce Flow testing?
Flow behavior is highly data-sensitive. Required fields, record types, lookup relationships, permissions, profile context, and related automation can all change the result. Poor test data can create false failures or false confidence.
How does natural-language testing help Salesforce QA teams?
Natural-language scenarios make tests easier for admins, QA engineers, business testers, and release managers to review together. When paired with execution trace, they connect business intent to technical evidence.
What is the TRACE framework?
TRACE is a practical framework for Salesforce Flow testing: Trigger with reliable data, Record the execution path, Assert node-level outputs, Capture evidence with timestamps, and Evaluate the result to improve the Flow and the test.
If your team is still relying on green debug runs as proof, it may be time to raise the standard. TestZeus helps Salesforce teams think beyond script execution and toward traceable testing evidence, where every important Flow test can explain not just whether something passed, but what actually happened.
// Start testing //







