

Jira Test Case Generation: Why QA Must Stop Rewriting Requirements Manually
Short answer: Jira test case generation works when AI drafts tests from the actual Jira requirement, not from a loose prompt. The goal is not to remove QA judgment. It is to stop forcing testers to manually translate stories, acceptance criteria, comments, and linked bugs into disconnected test artifacts that drift the moment Jira changes.
Introduction
A Jira story looks complete.
The user need is written down. The acceptance criteria are tidy enough. Product has added one late comment about an edge case. A linked production bug shows what failed last time. Somewhere in the thread, an engineer mentions that search performance must stay under 150ms.
Then QA opens another tool and spends an hour rewriting it all:
“Ensure the search bar supports Unicode characters.”
“Verify error state when database connection fails.”
“Test pagination when result set exceeds 50 results.”
“Confirm query response remains under 150ms.”
None of this is new thinking. It is translation work. Necessary, maybe. Valuable, sometimes. But mostly it is a hidden tax on QA teams that already have too much release pressure and too little time to investigate what actually matters.
The old assumption was simple: QA should manually convert requirements into test cases because that is how test design gets controlled.
That assumption is breaking.
QA should not be a requirements translation department. QA should be the trust layer between what the business intended, what engineering built, and what the release is about to ship.
The Hidden Translation Layer in QA
Jira already carries more product intent than many teams admit.
Stories describe the user need. Bugs reveal failure modes. Acceptance criteria define what “done” is supposed to mean. Comments capture nuance that never made it into the original description. Linked issues show technical dependencies, downstream damage, and previous release scars.
Then tests get written somewhere else.
Sometimes that means a spreadsheet. Sometimes it means a test management tool. Sometimes it means a separate Jira issue type, maintained through heroic linking discipline. Sometimes it means tribal memory plus a rushed regression checklist passed around before release week.
However it happens, the effect is the same: QA creates a second system of interpretation.
That second system is expensive. It eats hours. It introduces drift. A requirement changes in Jira, but the disconnected test case does not always get the memo. A product owner tightens one acceptance criterion. A comment adds a performance constraint. A linked bug changes the risk profile. QA has to notice it, reinterpret it, and manually update the test artifact somewhere else.
Disconnected tests are where requirements go to die.
The problem is not that QA teams cannot write tests. The problem is that too many teams still force testers to translate moving requirements by hand.
Research and Data: Traceability Is Not Admin Work
Requirement-to-test traceability is the practice of linking each requirement, story, or bug to the tests that verify it and the defects or results that relate back to it.
That sounds procedural until a release gets tense.
Then it becomes obvious that traceability is not admin work. It is release-confidence work.
NASA’s requirements management guidance emphasizes maintaining bidirectional traceability between expectations, requirements, design documents, test plans, and procedures. Its software engineering handbook also treats traceability between requirements, verification, and non-conformances as part of disciplined software assurance.
That is not because serious engineering teams enjoy paperwork. It is because validation becomes fragile when teams cannot follow the line from requirement to proof.
The same logic applies outside aerospace and safety-critical systems.
When a release manager asks whether a story is covered, traceability answers that. When a product owner changes an acceptance criterion late, traceability shows which tests are now suspect. When QA signs off, traceability turns signoff from a gesture into evidence. When a defect escapes, traceability helps the team see whether the requirement was weak, the test was stale, or the execution missed the mark.
Atlassian makes the practical version of this point in its guidance on acceptance criteria: clear, testable criteria reduce ambiguity and give QA a testing blueprint. That matters because vague requirements do not just slow teams down. They weaken the tests that get built from them.
Public QA and product communities keep circling the same pain. Ministry of Testing discussions ask whether tests should live inside stories or in separate tools, and how teams can keep requirement-to-test relationships from becoming manual clerical work. Atlassian Community threads show the problem at scale: hundreds of requirements, stories, and test cases, with teams trying to maintain links between them after the workflow is already moving. Reddit QA discussions surface the same pattern in rougher language: Jira is where the work lives, but test management often becomes another disconnected maintenance burden.
The research backs the lived experience. A Bosch empirical study of requirements defects over a five-year automotive project found that 61% of observed requirements defects stemmed from incorrectness or incompleteness, and that fix effort increased when those issues were found later. Other software engineering research has repeatedly connected ambiguous and changing requirements with weaker testing, redundant tests, irrelevant tests, and reduced fault detection.
For practitioners, this means wasted cycles rewriting, clarifying, and repairing stale tests.
For QA leaders, release managers, and engineering heads, it means weaker coverage visibility, weaker change impact analysis, and more false confidence than a green dashboard suggests.
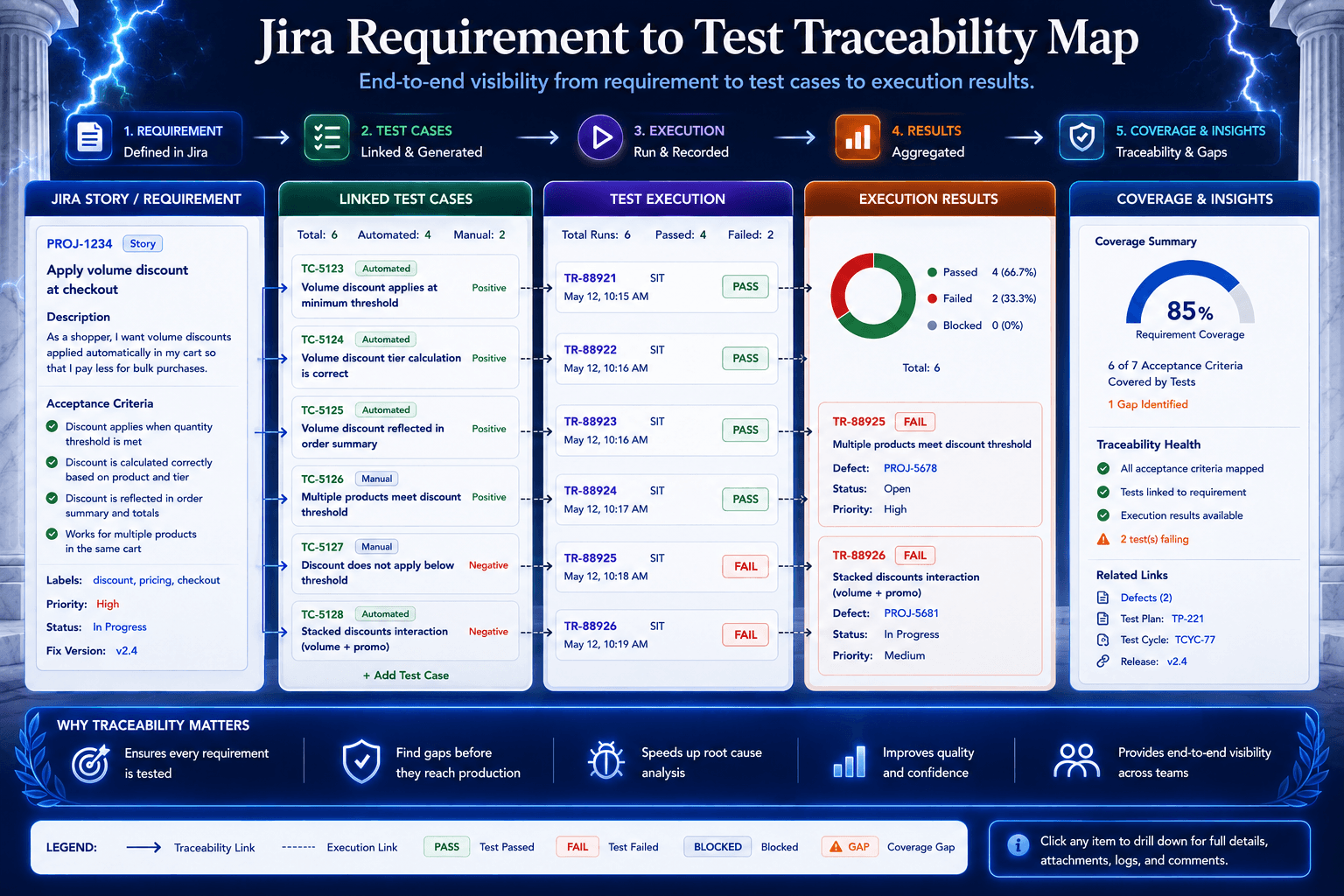
Why Jira Makes the Gap Visible
Jira did not create this problem. It exposes it.
Jira is where many teams track the current truth of delivery. Stories, bugs, epics, subtasks, comments, priorities, owners, labels, attachments, and linked issues all become part of the operational record.
But Jira alone is not a full test management strategy. Even in community discussions, practitioners say this bluntly: Jira is a ticketing and work management system, not a complete test management system out of the box.
So teams bolt on another process.
That second process is where the gap shows up. The story lives in Jira. The tests live elsewhere. Comments, linked bugs, revisions, late scope changes, and acceptance-criteria clarifications have to cross that gap manually.
The requirement changes in Jira. The disconnected test case does not always change with it.
That is the translation tax.
It does not appear as a clean line item in a QA budget. It shows up as late nights before release, brittle regression suites, test cases nobody fully trusts, and business stakeholders asking why something “covered” still broke in production.
What AI Changes, and What It Does Not
AI-assisted test generation is useful when it accelerates draft creation while keeping a human reviewer responsible for accuracy, relevance, and final approval.
That is the useful version. Everything else is noise.
The current research and vendor activity around AI-assisted test generation point in the same direction: large language models can draft acceptance criteria, test cases, BDD-style scenarios, positive paths, negative paths, edge cases, and boundary checks from requirement text.
That part is believable.
The dangerous part is pretending that a fluent model automatically understands the requirement better than the team does. It does not. NIST’s work on AI hallucinations is a useful reminder that language models can produce confident output that is wrong, incomplete, or unsupported. A generic prompt can produce generic tests. A polished draft can still miss the real business risk.
AI-generated tests are useful only when they are grounded in the source requirement and reviewed by a human.
The conclusion is not “stop thinking.”
It is “stop copy-pasting.”
From Generic Prompts to Requirement-Grounded Generation
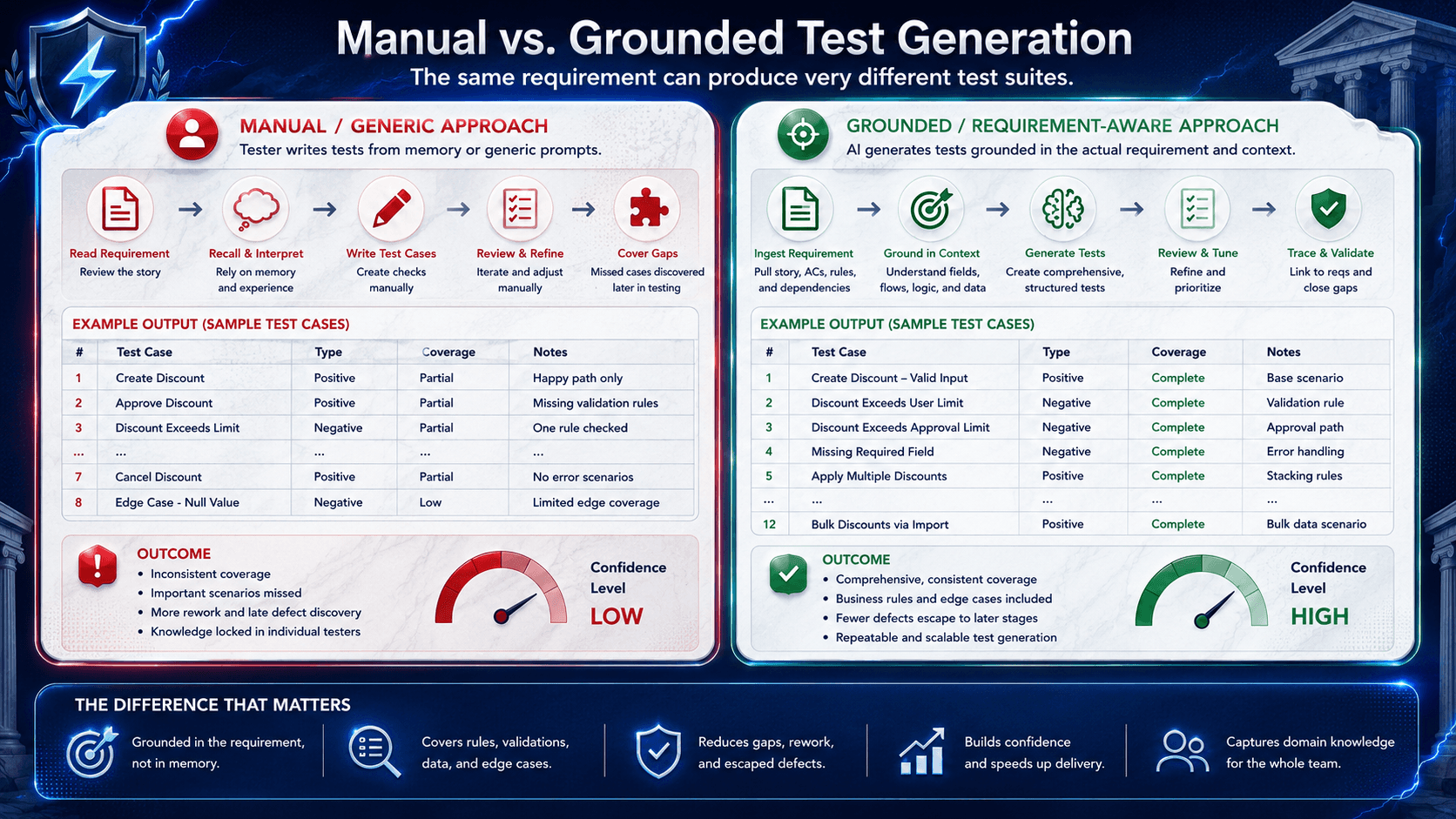
Jira-grounded test generation means generating draft test cases from the actual Jira story, acceptance criteria, comments, linked bugs, and related project context instead of from a generic prompt.
This is where grounding matters.
Research and cloud guidance around retrieval-augmented generation point to a practical principle: model outputs become more useful when they are tied to retrieved source context instead of relying only on broad model knowledge. In QA terms, a test draft should start from the real ticket, not from a vague instruction like “write tests for search.”
There is a world of difference between those workflows.
Approach | What QA is really doing | What usually breaks |
Manual rewriting from Jira into a separate artifact | Reinterpreting the requirement, retyping acceptance criteria, and recreating context by hand | Drift, stale tests, missed constraints, weak traceability |
Generic AI prompt without requirement grounding | Asking a model to guess from a broad description | Hallucinated steps, shallow coverage, missing business nuance |
Requirement-grounded Jira test case generation | Starting from the actual story, criteria, comments, and linked context, then reviewing the draft | Better first drafts, stronger traceability, still requires human judgment |
The market already understands the problem. TestRail, qTest, QMetry, Zephyr, BrowserStack, Provar, TestCollab, and other testing platforms all frame Jira integration around some combination of imported requirements, linked tests, execution visibility, and traceability.
The question is no longer whether requirement-to-test connectivity matters.
The question is why teams still tolerate manual sync, duplicate repositories, and copy-paste interpretation as the default operating model.
Connected source data beats clever prompting.
The Contrarian Point of View: More Test Cases Do Not Mean More Confidence
The stale belief is that QA teams need more test cases.
Not always.
Many teams already have plenty of test cases. What they lack is confidence that those tests still map to what the product is supposed to do.
A bloated test repository can look impressive while hiding three uncomfortable truths:
The tests may be stale.
The tests may not map back to current requirements.
The tests may verify old behavior that no longer matters.
That is why Jira test case generation should not be measured by volume alone. A tool that generates 100 shallow tests from a vague prompt is not helping. It is creating review debt.
The better goal is requirement-grounded coverage: fewer disconnected guesses, more tests that can point back to a source requirement, a business rule, a known defect, or a meaningful risk.
QA should not be rewarded for rewriting tickets faster.
QA should be empowered to ask better questions sooner:
Is the acceptance criterion testable?
What changed since this story was approved?
Which linked bug changes the risk?
Which generated tests are redundant?
Which business path is still uncovered?
Where is the requirement itself too vague to test responsibly?
That is the shift. AI should not turn QA into a faster test-case factory. It should move QA closer to the requirement while there is still time to improve it.
The TRACE Loop for Requirement-Grounded QA
If teams want a practical operating model instead of another AI slogan, start here.
T — Tie each test asset to a source requirement
If a test cannot point back to a story, bug, epic, or requirement, it is harder to trust and harder to update. Every generated test draft should have a visible parent.
R — Retrieve the surrounding context
A Jira summary is not enough. Pull in acceptance criteria, comments, linked bugs, related stories, attachments, and non-functional constraints. “Search performance must remain under 150ms per query” changes the test set in a way a generic user story will not.
A — Assess ambiguity before generation
Weak input produces weak tests. Before drafting, ask what is vague, missing, contradictory, or unmeasurable. This is where QA, product, and automation engineers align before a weak requirement becomes a weak release.
C — Create reviewable test variants
Generate happy paths, negative paths, edge cases, boundary conditions, permissions checks, and relevant non-functional checks in a format the team can review quickly. The point is not volume. The point is decision-ready coverage.
E — Evolve the trace when the requirement changes
When the Jira item changes, impacted tests, linked defects, and execution evidence should be visible. Otherwise teams discover drift late, when updates are more expensive and signoff becomes political.
TRACE turns requirement-connected QA from a one-time generation step into an operating model for coverage, change impact, and release confidence.
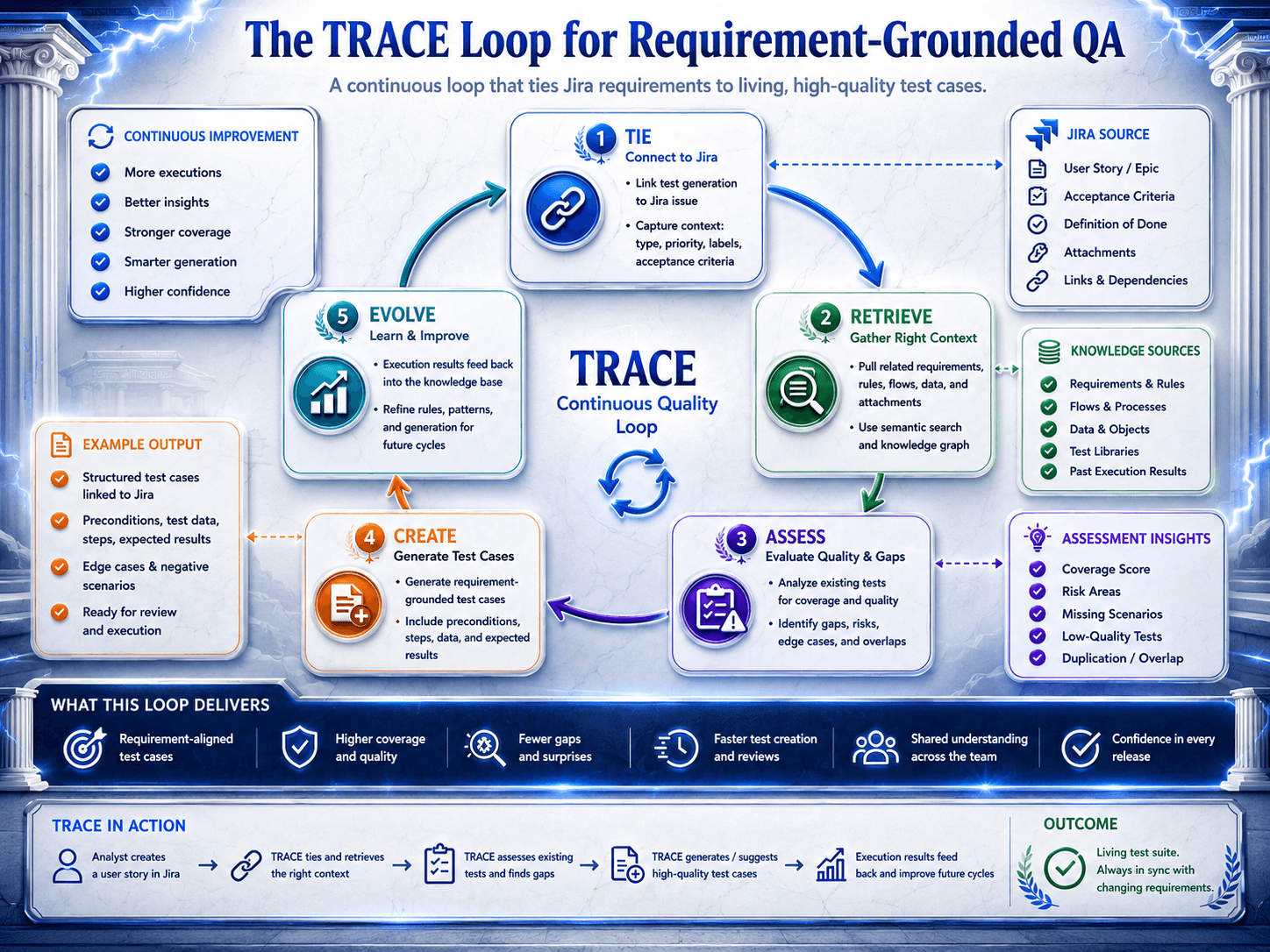
To see how this loop operates in practice, look at a concrete workflow in TestZeus.
What This Looks Like in TestZeus
The useful lesson from the TestZeus Jira workflow is not “there is a connector.”
It is that the test draft starts from the requirement instead of from a blank page.
Before the workflow changes, a QA engineer reads the Jira ticket, copies acceptance criteria into a separate tool, rewrites implied scenarios, checks comments for hidden constraints, remembers to include linked bugs, and hopes nothing changed after the test cases were written.
After the workflow changes, Jira becomes part of the testing context.
In TestZeus, a team can connect Jira through governed access, fetch the relevant issue into an approved knowledge base, review the retrieved record, and generate draft tests from that connected context. The important step is review: the Jira record is not treated as magic. QA approves the source context before generation begins.
From there, the team can create test drafts from the approved Jira item, choose the level of generation complexity, and produce one or many test cases for review. If the ticket includes a non-functional constraint such as “search performance must remain under 150ms per query,” that constraint can show up where it belongs: inside the testing conversation, not buried in a comment thread that someone may or may not remember.
That is the relief.
The QA engineer is no longer starting with a blank page and a copy-paste ritual. They are starting with a grounded draft that can be challenged, edited, rejected, expanded, and approved.
The valuable part is not that AI writes text.
The valuable part is that the draft starts from the real requirement.
The TestZeus Perspective
At TestZeus, we believe software testing is moving from script maintenance to agent supervision.
That does not mean testers disappear. It means their judgment moves to a better place in the workflow.
Instead of spending hours manually rewriting Jira tickets into test cases, QA teams can supervise generated drafts, assess ambiguity, strengthen coverage, and keep the relationship between requirements, tests, and results visible.
Jira integration matters not because a connector is impressive, but because disconnected authoring has become a hidden tax on modern QA.
Writing test cases from scratch is becoming the wrong default.
The stronger model is requirement-grounded generation, visible traceability, and human review at the point where judgment actually matters.
Practical Takeaways
Your test cases are only as good as your Jira tickets.
If the requirement is vague, the draft will be weak. If the acceptance criteria are shallow, coverage will be shallow. If the comments hide important nuance, QA needs that nuance in view. Connected generation does not erase those problems. It exposes them earlier, when the team can still act.
Smart QA teams should:
Treat Jira as source context, not just ticket storage.
Stop measuring test quality by test-case volume alone.
Link generated tests back to the requirement they verify.
Review AI-generated drafts as coverage proposals, not final truth.
Use ambiguity found during generation as feedback to product and engineering.
Keep requirement changes connected to impacted tests and results.
The future of QA is not a team of testers rewriting tickets faster. It is a workflow where requirements stay connected to tests, tests stay connected to results, and humans stay responsible for judgment.
QA should spend less time translating requirements and more time deciding whether the product is actually ready.
Explore how TestZeus thinks about requirement-grounded test creation.
FAQ Section
1. How do you generate test cases from Jira stories without rewriting them manually?
Connect Jira as the source of requirement context, fetch the relevant story or issue, review and approve the retrieved record, and generate draft tests from that approved context. QA still reviews, edits, and validates the output. The role shifts from retyping requirements to supervising coverage quality.
2. What is Jira test case generation?
Jira test case generation is the process of creating draft test cases from Jira issues such as stories, bugs, tasks, or epics. The strongest version uses the actual Jira requirement, acceptance criteria, comments, linked issues, and constraints as source context instead of relying on a generic prompt.
3. What is requirement-to-test traceability in QA?
Requirement-to-test traceability links each requirement, story, or bug to the tests that verify it, plus the results and defects that relate back to it. It helps teams prove coverage, understand change impact, and make release decisions with more confidence.
4. Why do test cases go stale when Jira tickets change?
They go stale when the requirement lives in Jira but the test lives in a disconnected artifact that has to be updated manually. Story edits, new comments, bug links, or revised acceptance criteria often do not make it into the test unless someone notices and rewrites it.
5. Can AI generate test cases from acceptance criteria?
Yes. AI can generate draft test cases from acceptance criteria and related requirement text, including positive, negative, edge, and boundary scenarios. Output quality depends on the quality of the requirement, the available context, and the strength of human review.
6. What should teams review before accepting AI-generated test cases?
Review the source requirement quality, missing or ambiguous criteria, non-functional constraints, business edge cases, permissions, linked defects, and whether each generated test still maps cleanly to the story being verified. Human review is the trust layer.
// Start testing //







