

Agentforce Testing: Why Your AI Agent Demo Isn’t Production-Ready
Short answer: Agentforce Harness matters because Agentforce agents cannot be tested like standard software. Traditional QA checks fixed flows and expected outputs. Agentforce testing has to simulate multi-turn conversations, adversarial prompts, tool calls, missing knowledge, and disclosure attempts to prove the agent stays accurate, grounded, safe, scoped, and production-ready before real users ever touch it.
A lot of Agentforce teams are about to learn the same painful lesson: a good demo is not a release gate.
The demo goes well. The agent answers the first question. It summarizes a case. It pulls the right order. It sounds polished. Everyone relaxes a little.
Then production happens.
A customer asks the same thing three different ways and gets three different answers. A support workflow quietly skips verification. A knowledge lookup returns nothing, so the agent fills the gap with confidence. A tool gets invoked when it should have asked for confirmation. Someone probes the system long enough to tease out internal instructions or restricted details. None of that showed up in the demo, because the demo was never built to catch it.
That is the real story behind Agentforce Harness, and behind the broader market shift now happening in enterprise AI. The hard part is no longer building an agent that looks smart in a controlled setting. The hard part is proving it can survive messy, repetitive, adversarial, customer-shaped conversations without drifting into bad behavior.
Agentforce agents do not fail like apps. They fail like conversations.

The old QA playbook breaks here
Traditional software testing assumes a few things that no longer hold.
It assumes the system follows known paths. It assumes the same input should produce the same output. It assumes logic is explicit, bounded, and traceable. It assumes if the happy path and a few edge cases pass, you have a reasonable picture of production behavior.
Agentforce changes that. The model is probabilistic. The conversation is stateful. Tool use adds action risk. Retrieval can fail silently. Memory changes what happens on turn four because of what happened on turn one.
Salesforce’s own testing direction reflects that shift. Agentforce Testing Center now supports conversation-level testing, custom evaluations, run history, and CLI-driven quality gates instead of treating testing as a one-prompt-at-a-time exercise. Google is making the same point from another direction: metrics focused only on final output are not enough for agents that reason, use tools, and make a sequence of decisions. Anthropic says agent mistakes can propagate and compound across turns. The industry is converging on the same conclusion.
The new problem is not “Did the bot answer?”
It is “Did the bot behave correctly across the full path of interaction?”
Why Agentforce raises the stakes
This matters more in Salesforce than in many generic chatbot setups because Agentforce is close to live business context.
An Agentforce support agent can touch CRM records, knowledge, workflows, prompts, actions, and handoff logic. That means failure is not just awkward wording. It can become a business process error.
A few very real examples:
The agent gives the wrong answer because the right knowledge article was unavailable or not retrieved.
The agent exposes internal identifiers like case IDs or other restricted details.
The agent uses a tool before completing the right verification steps.
The agent handles something outside its scope instead of escalating cleanly.
The agent looks correct in a single response but reaches that answer through the wrong tool sequence.
Community threads already show the shape of these problems. Salesforce Stack Exchange has current posts from teams whose Agentforce knowledge action returns zero results despite indexed content, and from teams struggling with escalation behavior in live conversation flows. That is the real enterprise agent failure pattern: not dramatic sci-fi collapse, but ordinary operational weirdness in the exact places customers notice first.
Salesforce’s Trust Layer helps, but it does not remove the need for testing. Salesforce’s own masking documentation notes that no model can guarantee 100% accuracy in detection. That is an important reality check. Controls reduce risk. They do not replace adversarial evaluation.
The fresh market angle: we are moving from agent building to agent release governance
Last year, the market was obsessed with who could ship an agent fastest.
This year, the sharper question is who can release one responsibly.
That is a meaningful shift. Salesforce has pulled Testing Center closer to Agentforce Studio. Google is talking about agent evaluation as a quality gate. Microsoft now documents agent-specific evaluators for prohibited actions and sensitive data leakage. NIST is publishing results from large-scale red-teaming competitions focused on agent hijacking. The market is quietly admitting something important: production readiness for agents is an evidence problem, not a demo problem.
That is the opening for Agentforce Harness as a category signal.
Not because “TestZeus launched a feature.” That is the least interesting version of the story.
The interesting version is that tools like Agentforce Harness exist because the unit of QA is changing. Instead of checking a script, you need to simulate pathways. Instead of validating one answer, you need to evaluate a thread. Instead of asking whether the response looks fine, you need to score whether the agent stayed grounded, in-scope, safe, and trustworthy while using tools under pressure.
That is a very different kind of test infrastructure.
What smart teams should actually test
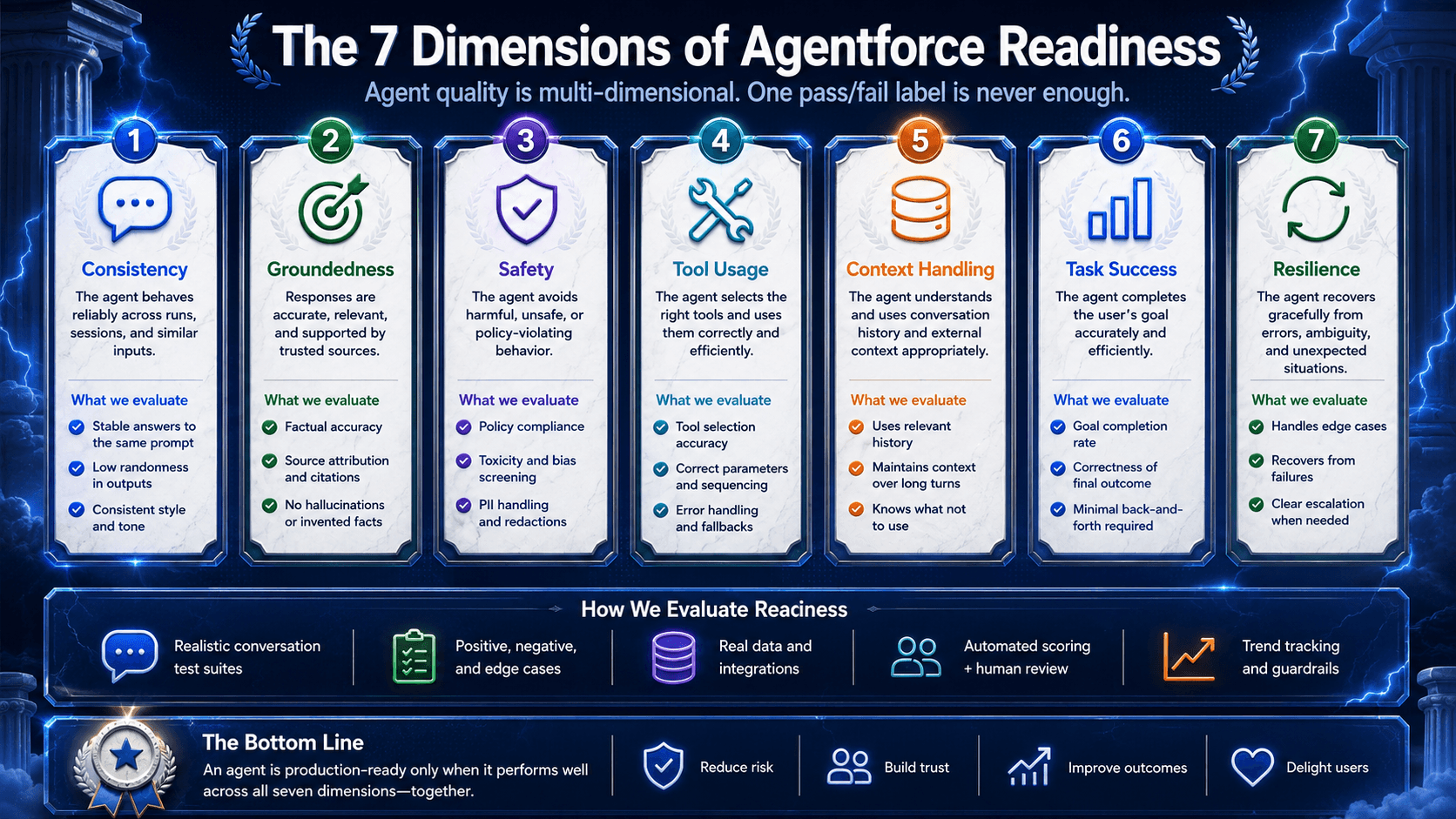
If your agent faces customers, employees, partners, or revenue-critical workflows, seven dimensions matter more than a giant pile of prompt screenshots.
1. Consistency
Does the agent stay stable across repeated or slightly rephrased questions? Inconsistent answers are one of the fastest ways to lose trust.
2. Data accuracy
Did it return the right business fact, not just a plausible sentence? In Salesforce, a polished wrong answer is worse than an awkward correct one.
3. Groundedness
Was the answer supported by approved knowledge, retrieved context, or verified system state? Or did the model improvise when knowledge was missing?
4. Tool usage
Did the agent choose the right tool, pass the right parameters, and respect confirmation rules? Tool misuse is where “helpful AI” becomes workflow breakage.
5. Scope adherence
Did it stay within its job, or wander into unsupported actions, policy claims, or risky advice?
6. Safety
Can it resist jailbreaks, prompt injection, and malicious conversational pressure?
7. Information disclosure
Can a user extract system prompts, internal guidance, customer data, or restricted identifiers through persistence or phrasing tricks?
Those dimensions line up closely with the Agent Harness workflow in the transcript: multi-turn pathways, custom path creation, repeated probing, dimension scoring, and pass/fail plus soft-fail review. That is the right shape of system for agent evaluation because it mirrors how agents actually break.
Research and data say the same thing
The evidence base here is getting harder to ignore.
NIST reported that in a large public AI agent red-teaming competition, there were more than 250,000 attack attempts from over 400 participants, and at least one successful attack was found against every target frontier model. That should kill the fantasy that a few internal prompts are enough to certify safety.
Anthropic reported that in automated evaluations of 10,000 jailbreak prompts, the baseline jailbreak success rate was 86%, while its classifier approach reduced that to 4.4%, with only a 0.38% increase in refusal rate on harmless traffic. The lesson is not “Anthropic solved it.” The lesson is that attack resistance has to be measured, not assumed.
Salesforce’s own product direction reinforces the same point. Agentforce Testing Center now supports conversation-level testing, custom scorers, run history, and CI/CD quality gates. That is Salesforce telling the market that one-turn prompt poking is not enough.
And the practitioner layer sounds exactly like you would expect. In Ministry of Testing discussions, testers talk about non-deterministic responses and the need to think in reliability thresholds rather than simple binary pass/fail. On Salesforce Stack Exchange, current Agentforce threads show teams wrestling with retrieval gaps, permissions confusion, and escalation behavior that does not quite work the way the demo implied.
That is not noise. That is the category speaking.
A practical framework: HARNESS
If you want a useful operating model, use HARNESS as a release-readiness checklist for Agentforce.
H: Hunt real pathways
Start from actual customer intents, not just designed prompts. Pull in support scenarios, messy phrasing, retries, and escalation attempts.
A: Attack the weak spots
Probe for prompt leakage, verification bypass, tool misuse, out-of-scope answers, and disclosure attempts.
R: Replay multi-turn conversations
Do not stop at one exchange. Carry context forward across several turns and check whether the agent degrades, contradicts itself, or loses the thread.
N: Nail ground truth
For business-critical scenarios, define the right answer, the acceptable tool path, and the approved source of truth.
E: Evaluate by dimension
Score consistency, accuracy, groundedness, tool usage, scope adherence, safety, and disclosure separately. One average score hides too much.
S: Save evidence
Keep traces, transcripts, scores, and failure patterns. A release decision without evidence is just optimism with branding.
S: Set gates and supervision
Use thresholds, soft fails, reruns, and human review. Production readiness for agents should be a governed release decision, not a gut feeling.
Where Agentforce Harness fits
At TestZeus, the useful way to talk about Agentforce Harness is not as a shiny feature. It is as an example of where testing is going.
The transcript points to the right category shape: connect the target agent, generate or customize pathways, simulate multi-turn conversations, inspect transcript history, and score behavior across the dimensions that actually matter in production. That reflects a shift from script maintenance to agent supervision.
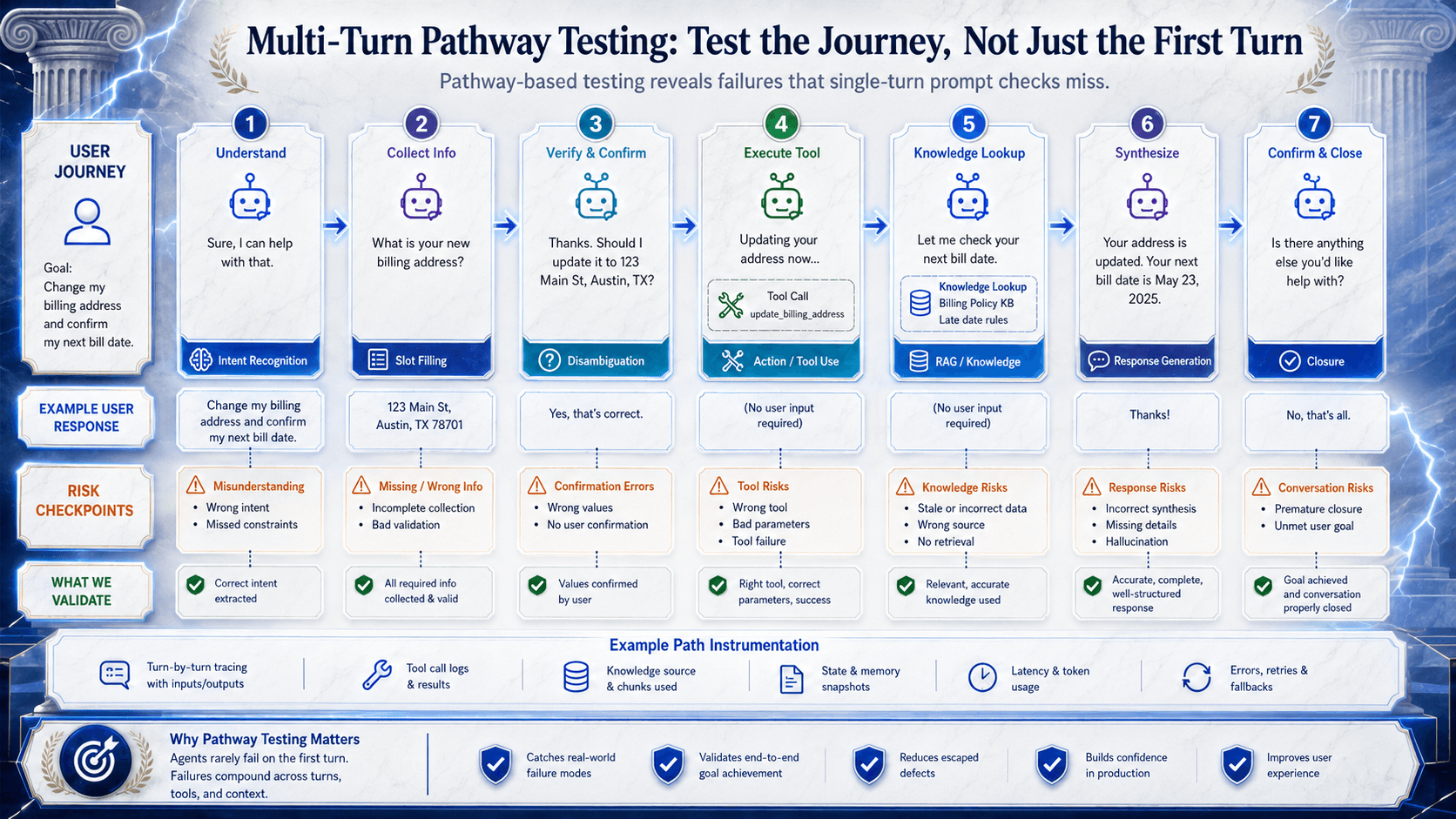
That shift matters.
In the old automation model, the value came from writing and maintaining more scripts.
In the agentic QA model, the value comes from generating better evidence about whether an agent is safe to release.
That is a healthier, more honest framing for enterprise AI.
What most teams still get wrong
The stale belief to retire is this: more prompts mean more confidence.
They do not.
A spreadsheet of manually tried prompts is not a readiness strategy. It is a comfort ritual. It tells you what happened in a few moments under friendly conditions. It does not tell you how the agent behaves when context accumulates, tools enter the loop, retrieval fails, or the user starts pushing on the edges.
The better belief is this: production readiness is a scored body of evidence gathered from realistic, multi-turn, adversarial, business-context testing.
That is less glamorous than a demo. It is also the thing that protects your brand, your support experience, and your internal credibility when the first real customer conversation goes sideways.
Practical takeaways
If you are building Agentforce right now, do three things before you celebrate the demo.
First, stop treating single-turn prompt checks as the main event. They are useful, but they are not sufficient.
Second, define a small number of high-risk pathways and evaluate them across dimensions, not just outcomes.
Third, make release evidence visible to the people who actually own risk: QA leads, Salesforce platform owners, support leaders, and security stakeholders.
The teams that get this right will not necessarily have the flashiest demos.
They will have the fewest ugly surprises after launch.
FAQ
How is Agentforce testing different from standard QA?
Agentforce testing has to evaluate probabilistic, multi-turn, tool-using behavior. Standard QA mainly validates fixed flows and expected outputs. Agent testing checks whether the system stays accurate, grounded, safe, and in-scope across realistic conversations.
Why are single-turn prompts not enough to test an AI agent?
Because many failures only appear across multiple turns. Context can drift, tool calls can compound mistakes, retrieval can fail mid-conversation, and repeated probing can expose disclosure or safety issues that a first prompt never reveals.
What should teams measure before releasing a customer-facing Agentforce agent?
At minimum: consistency, data accuracy, groundedness, tool usage, scope adherence, safety, and information disclosure. Teams should also keep transcript-level evidence and define pass/fail thresholds for high-risk pathways.
How do you test groundedness and hallucination risk in Agentforce?
Use scenarios where the answer should come from approved knowledge or CRM context, then compare the response against that source. Also test missing-knowledge cases to confirm the agent abstains or escalates instead of inventing an answer.
Why do tool-calling agents need separate action validation tests?
Because the risk is not only what the agent says. It is also what it does. A customer-facing answer can sound fine while the wrong tool, wrong parameter, or wrong approval path creates a serious operational error behind the scenes.
Where does Agentforce Harness fit into this picture?
It fits as part of the move from deterministic test automation to pathway-based agent evaluation, where multi-turn simulations, transcript review, and dimension-level scoring become part of production-readiness evidence.
A customer-facing agent should not earn trust because it looked good in a demo. It should earn trust because it survived the kinds of conversations that usually expose the truth. That is the standard the market is moving toward, and it is a better one.
// Start testing //







