

QA Reporting Is Broken: Move Beyond Pass/Fail Counts
Short answer: What is agentic QA reporting?
Agentic QA reporting uses AI-driven analysis to turn raw test results into decision-ready summaries. Instead of only showing pass/fail counts, it identifies failure patterns, suspected bugs, affected runs, evidence links, and recommended next steps so QA leads, engineers, and business stakeholders can understand what matters after a test run.
Robin checks his phone at 7:04 AM.
The overnight regression run finished. The dashboard says 247 passed, 19 failed, and 3 skipped.
That should be the end of the work. It is not.
Now comes the harder part: explaining whether those 19 failures mean “do not ship,” “rerun in staging,” “file one bug,” “ignore flaky noise,” or “wake up the Salesforce team before the release call.”
This is where QA reporting usually breaks. The numbers are easy. The meaning is the work.
QA reporting is the process of translating test execution results into clear quality insights, risks, evidence, and recommended actions for engineering and business stakeholders.
A pass/fail count is not that. It is only the opening sentence.
Pass/Fail Counts Are the Beginning, Not the Report
A pass/fail count tells you what happened. It does not tell you what matters.
That difference is where release confidence lives. A report that says “19 tests failed” still leaves the QA lead with the real work: which flows broke, whether the same bug caused multiple failures, which failures are noise, and whether any of this should block the release.
This is why QA reporting is not a spreadsheet problem. Most teams do not lack test results. They lack test meaning.
A pass/fail dashboard says:
19 failed.
A decision-ready QA report says:
Nineteen failures came from three clusters. One appears to be a shared authentication issue affecting quote approval. Two are likely flaky environment failures. Core checkout and customer login flows passed. Recommendation: block only if quote approval is part of this release.
That is the difference between test status and release judgment.

The Report Nobody Reads Is Still a Bug
If your report sits unread, it creates decision lag: the costly delay between test finish and release go/no-go.
Most QA teams have lived this. Someone posts the dashboard. Then the questions begin.
What failed?
Is it real?
Which environment?
Is there a screenshot?
Does this affect customers?
Is this the same issue as yesterday?
Can we ship anyway?
The report existed, but the decision still had to be rebuilt in Slack, Jira, or a release meeting.
If the report needs a meeting to explain it, the report is not finished.
This is not about making reports longer. In fact, longer reports often make the problem worse. Executives do not want raw logs. Engineers do not want vague summaries. Release managers do not want twenty screenshots without a recommendation.
A useful report reduces the number of people asking, “So what does this mean?”
QA Reporting Is Translation Work
The QA lead’s job is not to forward logs. It is to turn test evidence into release confidence.
Engineers need the exact failure path. Product leaders need impact. Release managers need a go/no-go signal. Business stakeholders need to know whether a workflow they care about is blocked.
Those are not the same request.
This is why a single QA dashboard often fails different audiences in different ways. It is too shallow for engineering and too noisy for leadership. The same artifact tries to serve debugging, executive reporting, compliance review, and release decision-making.
Good QA reporting changes shape without losing truth. The summary should get clearer as the audience gets farther from the failure. The evidence should get deeper as the audience gets closer to fixing it.
That is the reporting job most teams underestimate.
Dashboards Show Status. Reports Should Create Decisions.
A QA dashboard is useful. It gives teams a shared view of test execution reporting: total tests, passed tests, failed tests, skipped tests, duration, and sometimes environment or branch.
But a dashboard is not automatically a report.
A pass/fail dashboard shows raw test status, while an intelligent QA report explains what the status means, what patterns matter, and what decision the team should make next.
That distinction matters more in modern test automation reporting because teams are producing more test data than humans can comfortably interpret at release speed.
Hundreds of automated test reports can be generated in a week. Nightly regression test reporting can produce thousands of pass/fail events. AI test reports should not simply summarize that noise in prettier language. They should help separate signal from noise.
The old reporting question was: “How many tests failed?”
The better reporting question is: “What should we do because these tests failed?”
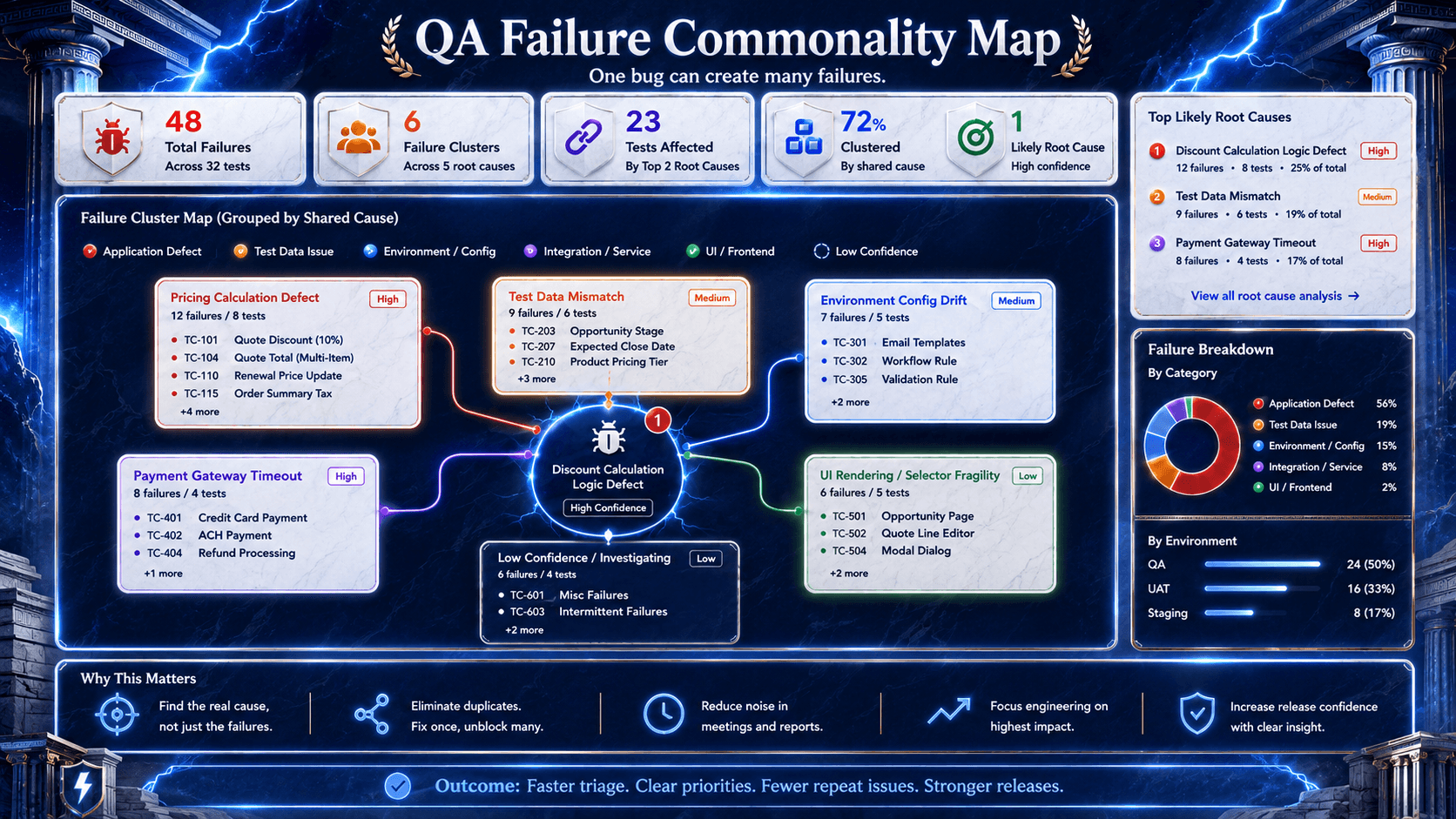
Reports Should Find the Pattern Before the Standup Does
One bug can make ten tests fail.
That sounds obvious until the report treats every red row like a separate incident.
A useful QA report should group failures that share the same symptom, environment, component, test data, or likely root cause. If login instability causes downstream failures in product search, checkout, and account update flows, the report should not make the team discover that manually.
This is where agentic QA reporting becomes more than a nicer dashboard. Agentic QA reporting uses AI-driven analysis to summarize outcomes, identify common failure patterns, surface suspected bugs, and recommend next steps from test execution data.
The useful part is not that AI writes a paragraph. The useful part is that the report starts doing the analytical work a senior QA lead would otherwise do under pressure.
It clusters related failures.
It separates likely product bugs from likely environment noise.
It points the team toward the first thing worth investigating.
Community conversations around QA reporting often circle the same frustration: QA teams provide what they think is enough information, but developers still say something is missing. Usually, what is missing is not another artifact. It is the story that connects the artifacts.
Reports should find the pattern before the standup does.
Evidence Makes the Report Actionable
A confident summary without evidence is just better-looking ambiguity.
Every serious test failure analysis needs proof. Screenshots, videos, logs, steps, execution timelines, environment details, and direct failed run links are not “extras.” They are what make a report credible.
Evidence helps engineering move faster because the failure is already reproducible enough to inspect. Evidence helps leadership trust the summary because the conclusion is traceable. Evidence helps QA avoid becoming the human search engine for every failed run.
In one TestZeus Agentic Reports workflow example, a failed test does not stop at a red status. The report opens into a failure summary that explains why the run failed, including a case where a JavaScript prompt dialog did not appear. The same report includes environment details, performed steps, generated artifacts, and a link back to the Test Runs page.
That Test Runs page gives the debugging layer: status, process, video playback, artifacts, individual steps, and execution timelines.
That is what a modern QA report should do. It should give leaders the summary and engineers the trail.
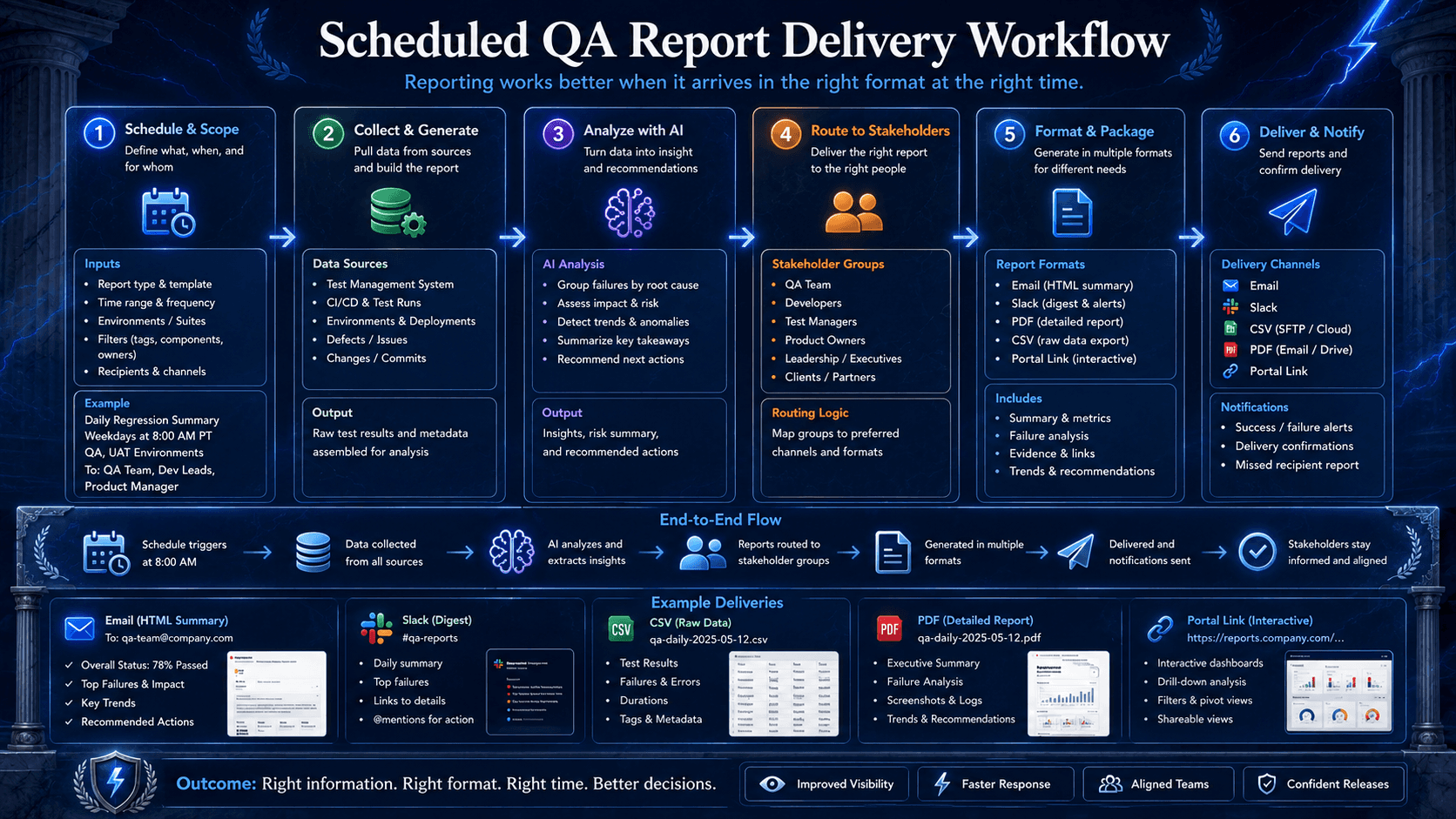
Scheduling Turns Reporting Into a Rhythm
A report that includes everything usually explains nothing.
The best reports are scoped. They are bound by time window, test run pattern, environment, tag, release, or business process. That scope is not a constraint. It is what keeps the report useful.
Morning reports should answer a morning question. Nightly regression reports should answer a regression question. Release reports should answer a release question.
When teams dump every test, every environment, and every exception into one artifact, they do not create visibility. They create a warehouse.
In a TestZeus reporting workflow, a QA lead can use a Report Scheduler to define a report name, test run name pattern, scheduled or historical time window, and filters such as tags, data, and environment. Operators like IN and LIKE help keep reports focused instead of universal.
That matters because good reporting is not only about analysis. It is also about timing.
The right report delivered too late is still the wrong report.
The Right Format Depends on the Reader
People do not consume QA information the same way.
A release manager may want an email summary before the morning call. An engineer may want a Slack notification with a link straight to the failed run. A QA analyst may want CSV for slicing results. A platform owner may want a polished PDF for leadership review, audit, or sharing outside the test tool.
Format is not cosmetic. It determines whether the report gets used.
In a TestZeus Agentic Reports example, the email includes a Consolidated Test Analysis, a high-level summary grid for total, passed, failed, and skipped tests, and direct links back to individual test runs. The same report can include CSV and PDF attachments for analysis and circulation.
That is closer to how real organizations work.
One report. Multiple consumption modes. Shared conclusions.
Old Reporting vs. Decision-Ready Reporting
Reporting style | What it delivers | What the team still has to do |
Pass/fail dashboard | Counts of total, passed, failed, and skipped tests | Interpret whether the failures matter |
Static spreadsheet or email recap | Raw results with a few notes | Rebuild failure groups, impact, and next steps in meetings |
Decision-ready agentic report | Summary, commonality, suspected bugs, evidence links, and recommended actions | Validate the recommendation and move into fix, rerun, or release |
The Report Room: What Every QA Report Must Answer Before Anyone Joins a Meeting
Most QA status meetings exist because the report did not finish the job.
If a report only says “247 passed, 19 failed, 3 skipped,” it has not answered the release question. It has only started the conversation. The QA lead still has to explain which failures matter, whether the same bug caused several failures, whether the issue blocks a release, and where engineering should look first.
A strong QA report should walk into the room before the QA lead does.
Before a QA report reaches Slack, email, or the release room, it should pass five questions.
1. What changed since the last report?
Not just the current pass/fail count. The report should explain whether quality improved, declined, or shifted in a specific area.
Did a flaky environment settle down? Did a once-stable Salesforce approval flow suddenly start breaking? Did failures move from cosmetic UI issues into quote generation or permissions?
Change is the story. Raw totals are only the backdrop.
2. Which failures are connected?
A useful report should group failures that share the same symptom, environment, component, test data, or likely root cause.
One bug can create ten red tests. The report should not make the team discover that manually.
If login instability caused downstream failures in opportunity creation, pricing, and checkout, the report should say so plainly. Otherwise, the team wastes time treating one incident like ten separate problems.
3. What is the business risk?
A failed test in a low-priority UI path is not the same as a failed Salesforce quote, payment, login, or order flow.
The report should translate test failure into release impact.
What can users not do? What revenue path is exposed? What internal workflow is blocked? A report that cannot separate nuisance from risk forces everyone else in the meeting to do that translation live.
4. Where is the proof?
Every summary should link back to the evidence: screenshots, videos, logs, steps, execution timelines, and failed run pages.
Without evidence, the report creates another round of questions.
People ask for the replay, the stack trace, the exact step, the environment, the timestamp. By then, the report has stopped being useful and started becoming homework.
5. What should happen next?
The report should recommend the next move: ship, block, rerun, investigate, file a bug, fix the environment, or review flaky tests.
This is where many QA reports go quiet. They describe the mess but avoid the decision.
A report does not need to pretend it has perfect certainty. It does need to help the team move.
A report that answers these questions does not replace judgment. It protects judgment from being buried under raw data.
The best QA report is not the longest one. It is the one that reduces the number of people asking, “So what does this mean?”
What This Looks Like in TestZeus
At TestZeus, Agentic Reports reflect a broader shift from static reporting to test-result intelligence.
The useful part is not that another report exists. The useful part is that the report helps the team decide what to do next.
Part 1: The Agentic Difference
In a TestZeus Agentic Reports workflow, the Reports tab shows the basics first: report status, report name, covered test runs, and who modified the report.
That is the expected layer.
The more important layer is the Consolidated Test Analysis. Instead of leaving the QA lead with only total, passed, failed, and skipped counts, the report adds AI analysis, commonality, exploration paths and failures, bugs and main issues, and recommended next steps.
That is the shift from “what happened?” to “what should the team understand?”
The Test Results tab adds the run-level view. A failed test can show an output summary, the reason for the failure, environment details, steps performed, and artifacts generated. In one example, the report explains that the JavaScript prompt dialog did not appear.
That is specific enough to help engineering start investigation without waiting for a separate explanation.
Part 2: The Delivery Mechanism
The second part is rhythm.
A QA lead can create a Report Scheduler, define a report scheduler name, use a test run name pattern such as “search,” choose a scheduled or historical time window, apply IN and LIKE filters across tags, data, and environment, and select notification channels.
Reports can also be created from test execution. A user can select specific tests, such as an accessibility test, product search test, or JavaScript dialog test, trigger the run, choose notification channels, and have the report entry created automatically.
The delivery format then matches the audience. Email gives the summary. Portal links preserve drill-down. CSV supports analysis. PDF supports leadership review and sharing.
This is the practical lesson: agentic QA reporting is not just about analysis. It is about getting the right explanation to the right person before the release decision gets stuck.
Soft CTA: Explore how TestZeus thinks about agentic QA reporting: https://www.testzeus.com
The Real Shift in QA Reporting
At TestZeus, we believe QA reporting should move beyond pass/fail counts.
A useful report should explain what failed, what failures have in common, which issues look like real bugs, what evidence supports the conclusion, and what the team should do next.
That is not just a tooling opinion. It is a workflow opinion.
Testing is moving from script maintenance to agent supervision. Reporting is moving with it. The old model assumed teams needed help producing more execution data. The new model assumes teams need help interpreting execution data before release decisions stall.
This is especially true for Salesforce and enterprise application QA. A broken automated test is rarely just a broken test. It may represent a quote approval issue, a permissions problem, a revenue workflow risk, or a blocked internal operation.
That is why QA reporting has to speak both languages: the technical language of failure evidence and the business language of risk.
Conclusion
QA reports should not be a weekly paperwork ritual.
They should help teams move from raw test results to confident release decisions. They should tell leaders whether the business is exposed, tell engineers where to look, and tell release managers what should happen next.
The goal is not to make reports bigger. The goal is to make them harder to ignore.
Your test report should tell you what matters, not just what failed.
Dashboards tell you what happened. Reports should tell you what to do.
FAQ Section
1. What is agentic QA reporting?
Agentic QA reporting uses AI-driven analysis to turn test execution results into decision-ready summaries. It groups related failures, surfaces suspected bugs, links to evidence, and recommends next steps so QA leads, engineers, and stakeholders can act faster after a test run.
2. Why are pass/fail QA reports not enough?
Pass/fail QA reports are not enough because they show status without meaning. They do not explain whether failures are connected, whether they affect business-critical workflows, whether they are likely bugs, or what action the team should take next.
3. What should a modern QA report include?
A modern QA report should include scope, environment, time window, pass/fail/skipped counts, failure explanations, grouped commonality, business impact, recommended next actions, and direct links to artifacts such as logs, screenshots, videos, steps, timelines, and failed run pages.
4. How can AI improve test reporting?
AI can improve test reporting by clustering similar failures, summarizing outcomes in plain language, identifying likely root causes, surfacing suspected bugs, highlighting business risk, and recommending whether teams should ship, block, rerun, investigate, or file a bug.
5. Why should QA reports link to artifacts like logs, screenshots, and videos?
QA reports should link to artifacts because evidence makes summaries trustworthy and actionable. Engineers can debug faster, QA leads can defend conclusions, and stakeholders can understand the basis for release recommendations without asking for a separate explanation.
// Start testing //







