

Prompting Is Not Enough. AI Testing Agents Need Grounding.
Short answer: AI testing agents become reliable when they stop guessing.
Better prompts help, but they do not solve the real QA problem: agents need reusable context about environments, data, tenant rules, and execution boundaries.
In Salesforce especially, grounded agents outperform prompt-only workflows because the failure risk usually lives in organization-specific details, not in how elegantly someone phrased a test step.
Most AI testing agents do not fail because they are incapable.
They fail because we ask them to improvise inside systems that punish improvisation.
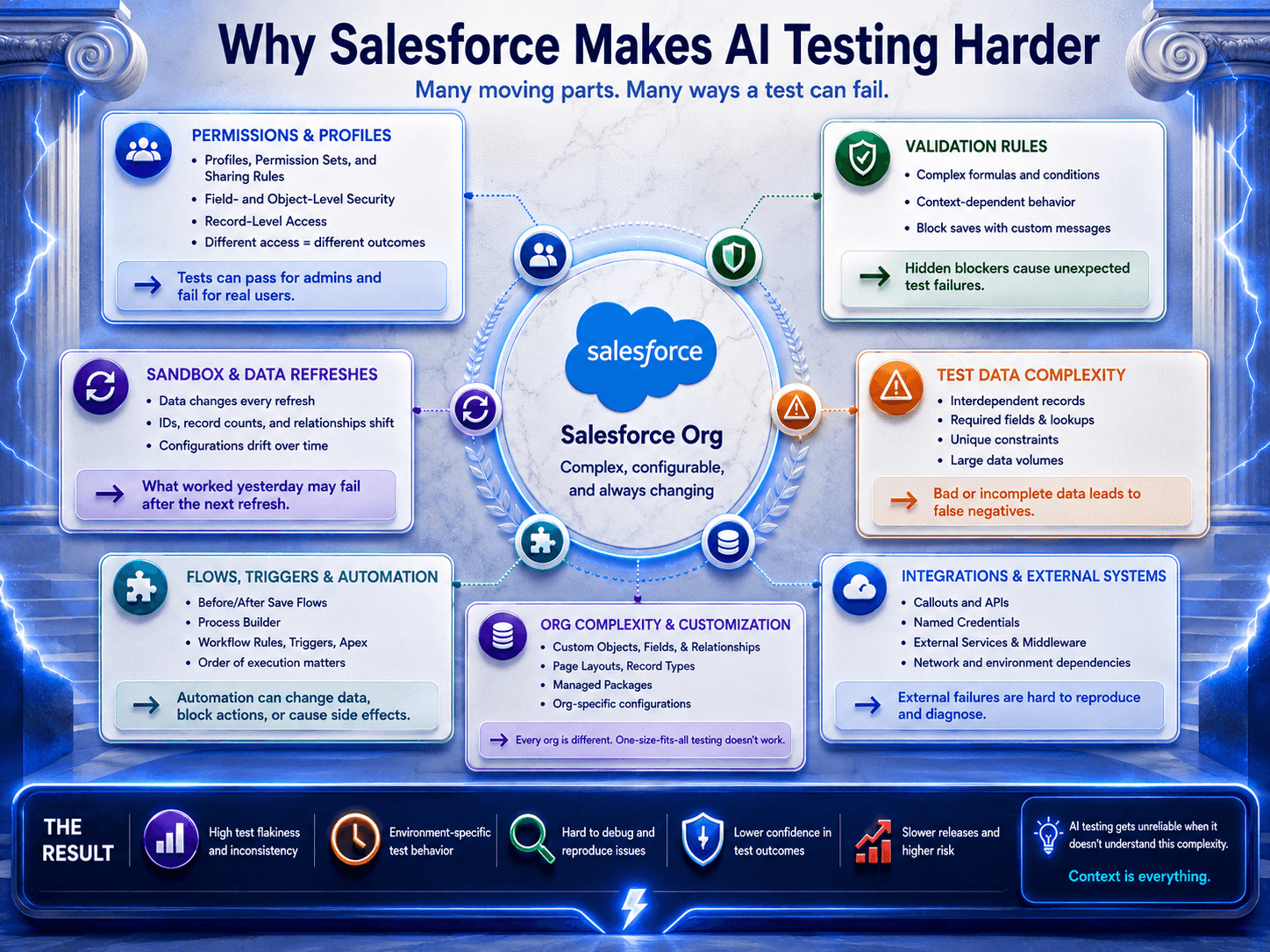
That matters more in Salesforce than in almost any other enterprise stack.
A test is never just a test. It is a specific user, in a specific org, with a specific permission set, against a specific environment, using data that may or may not survive the next sandbox refresh.
Community discussions repeatedly surface the same pattern: manually seeded data disappears after refreshes, integrations need reconnecting, documentation is incomplete, and business logic sprawls across overlapping Flows, validation rules, formulas, and workarounds that nobody fully trusts anymore.
So when people say, "We just need better prompts," they are solving the wrong problem.
A prompt can tell an agent what to do.
It cannot reliably tell the agent which staging URL matters this week, which tenant rules override defaults, which test user is valid in UAT, or which business-specific assumption should win when local instructions conflict.
That is not a writing problem.
It is a context architecture problem.

The Real Breakpoint: Why Context Architecture Trumps Prompting
Consider a common enterprise testing scenario.
A QA team deploys an AI agent to validate a Salesforce case creation workflow. The agent successfully finds every button, completes every field, and submits the record.
The test still fails.
Not because the agent could not click Save, but because it had no knowledge that this region requires an additional validation rule that only applies to European accounts.
The hard part was never clicking the button.
The hard part was understanding the context.
This aligns closely with guidance from both Salesforce and OpenAI.
Salesforce's AI guidance repeatedly emphasizes trusted data, grounding, guardrails, monitoring, and explicit instructions as prerequisites for reliable agent behavior.
Salesforce Trusted AI: https://www.salesforce.com/artificial-intelligence/trusted-ai/
Salesforce Agentforce Documentation: https://help.salesforce.com
Salesforce Trailhead Agentforce Guidance: https://trailhead.salesforce.com
Similarly, OpenAI's guide to building agents highlights structured context, evaluation loops, guardrails, and human oversight for high-risk workflows.
OpenAI Guide to Building Agents: https://platform.openai.com/docs/guides/agents
That is the deeper shift happening in agentic QA.
The real transformation is moving from fine-tuning prompts to building a contextual operating model.
In early demonstrations, prompt-only testing feels magical. Paste a few instructions, point the agent at a workflow, and it does something impressive.
Production QA is where the bill comes due.
The same test can quietly drift because:
The environment changed.
The org metadata changed.
The browser assumption changed.
The user changed.
The data changed.
In other words:
Ungrounded agents are the new flaky tests.
Why Salesforce Teams Feel This Faster
Salesforce QA has always been more contextual than people admit.
The hard part is rarely clicking a button.
The hard part is knowing:
Which org contains the correct configuration.
Whether a profile can see the required field.
Whether a validation rule fires only in one region.
Whether an approval path differs by business unit.
Whether the sandbox still reflects production reality.
Community discussions around refresh pain, bad orgs, and test data instability read less like edge cases and more like field reports from everyday enterprise operations:
Massive field counts.
Undocumented logic.
Overlapping Flows.
Hidden dependencies.
Sandbox refresh cycles that distort or erase critical test data.
This is exactly why prompt-only agentic QA becomes brittle.
It forces humans to manually reattach business context during every run.
The result is a new maintenance burden.
Instead of babysitting Selenium locators, teams babysit prompt context.
That is not progress.
It is script maintenance wearing better clothes.
The Dangerous Trap: Why Ungrounded Agents Create False Confidence
One outdated assumption continues to surface:
If the agent gets smarter, the prompt can remain in control.
No.
Smarter agents increase the cost of ambiguous context.
Traditional automation scripts usually fail loudly.
Ungrounded agents can fail politely.
They may:
Choose the wrong URL.
Use the wrong tenant.
Execute in the wrong environment.
Validate the wrong outcome.
Produce convincing-looking reports.
That is more dangerous than a visible failure because it creates false confidence.
Salesforce's own trust framework positions guardrails as mechanisms that reduce ambiguity and anchor agents to real business context.
The QA community is reaching the same conclusion.
Teams report strong results from AI when agents operate within structured frameworks and rich application context.
The disappointing stories almost always share one characteristic:
The context was missing.
A Practical Framework: From Prompt Chaos to Grounded Execution
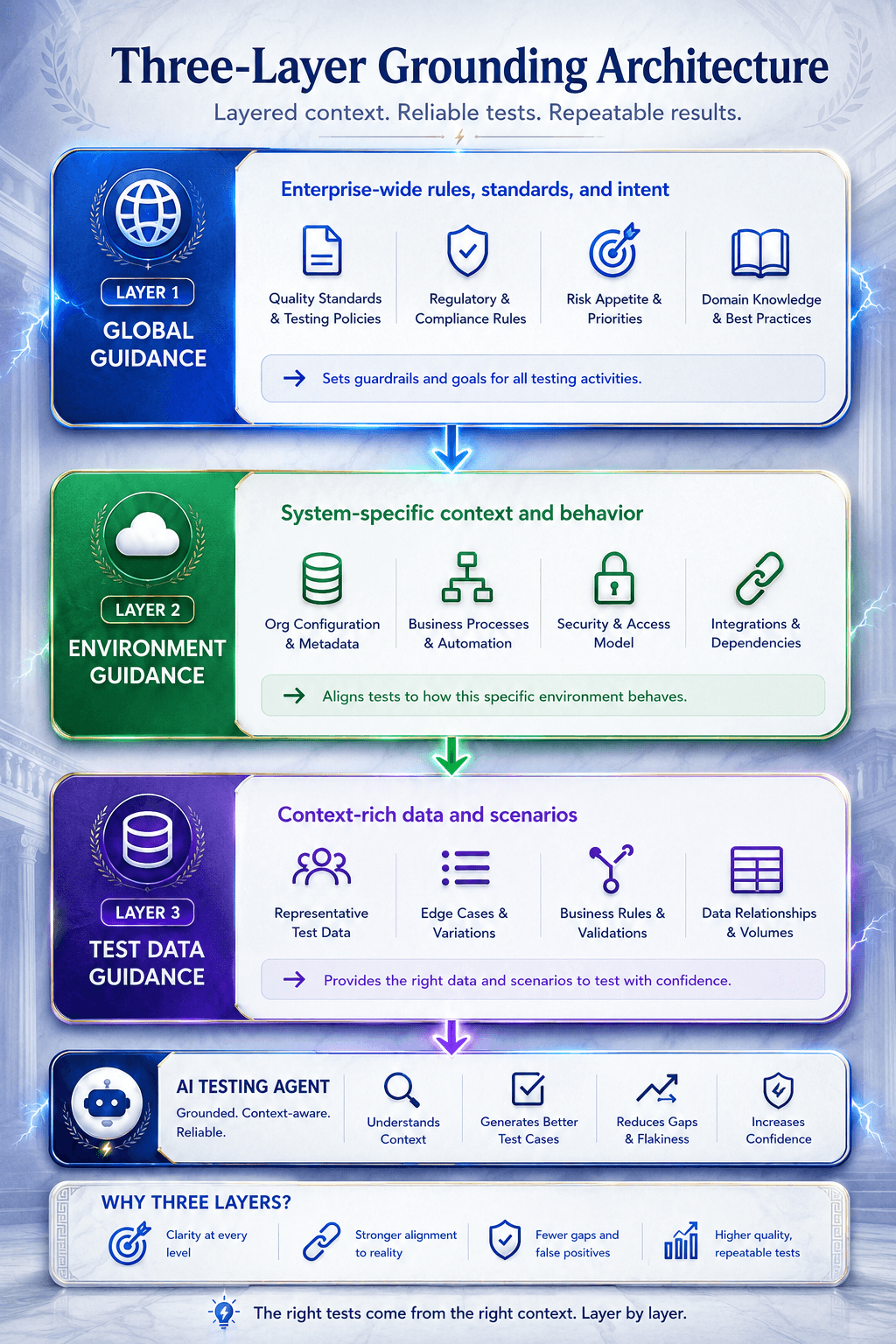
Reliable agentic QA requires separating context into distinct layers.
Layer 1: Global Guidance
Rules that apply across the organization.
Examples:
Preferred browser
Homepage expectations
Compliance requirements
Organization-wide execution rules
Layer 2: Environment Guidance
Rules tied to specific environments.
Examples:
Sandbox URLs
UAT credentials
Integration configurations
Environment-specific restrictions
Layer 3: Test-Data Guidance
Instructions attached directly to the scenario.
Examples:
Dataset requirements
Record assumptions
Account context
Workflow-specific input rules
The most important principle is priority.
The most specific rule should win.
That is where the most expensive QA failures usually occur.
Bringing the Framework to Life
A framework only matters if teams can operationalize it.
This is where grounded agent execution becomes practical rather than theoretical.
The goal is not simply to store context.
The goal is to make context reusable, governable, and inherited automatically by the agent at runtime.
What This Looks Like in TestZeus
One practical expression of this approach is TestZeus Agent Guidance.
Instead of stuffing every instruction into individual test steps, guidance can live at:
The global account level
The environment level
The test-data level
That distinction matters.
For example:
A test step that says:
"Given a user navigates to Nike"
should not require the URL to be repeated in every scenario.
If the correct URL already exists within the attached test-data context, the agent should inherit it automatically.
Likewise:
Environment-specific URLs should live with the environment.
Test-user credentials should live with the environment.
Browser defaults should live at the account level.
Workflow-specific assumptions should live with the scenario.
The value is not the feature checklist.
The value is the operating model.
Scoped guidance transforms context into infrastructure.
It makes agent behavior:
More reusable
More auditable
Easier to govern
Easier to scale
This aligns with the broader direction of agentic QA: moving away from script maintenance and toward agent supervision.
For teams exploring this model, see:
TestZeus Agent Guidance (Internal Link Opportunity)
TestZeus on Test Data Management (Internal Link Opportunity)
Practical Takeaways
Stop evaluating AI testing agents solely by how well they follow prompts.
Evaluate them by how effectively they use scoped context.
Treat environments, tenants, test data, and execution rules as first-class testing assets.
If an agent guesses incorrectly, investigate grounding before blaming the model.
In Salesforce, assume missing context will create false confidence before it creates obvious failures.
Build systems where specific guidance overrides general guidance.
That is how organizations operate.
Your testing architecture should reflect that reality.
FAQ
Are better prompts enough to make AI testing agents reliable?
No. Better prompts improve clarity, but reliability comes from grounding, guardrails, and reusable context. Both Salesforce and OpenAI emphasize structured instructions, trusted data, and governance mechanisms rather than prompt engineering alone.
What does grounding mean in QA?
Grounding means attaching the agent to the correct context so it does not need to guess. This includes environments, users, datasets, business rules, browser assumptions, and workflow-specific instructions.
Why is grounding especially important in Salesforce testing?
Because Salesforce testing depends heavily on org-specific context. Sandbox refreshes, permissions, undocumented logic, overlapping automations, and hidden dependencies can all affect outcomes without changing the test itself.
Does grounding replace human testers?
No.
It changes their role.
Instead of maintaining brittle scripts, testers increasingly supervise context quality, review evidence, verify business intent, and strengthen guardrails.
What is the best place to store agent guidance?
At the narrowest level that remains reusable.
Global rules belong globally.
Environment rules belong with environments.
Scenario rules belong with test data.
This reduces accidental overrides and improves maintainability.
What should teams do first?
Audit where critical context currently lives.
If URLs, users, business rules, test data assumptions, and execution constraints mostly exist in prompts, tickets, or tribal knowledge, that is the first reliability problem to solve.
If your team is experimenting with AI testing agents, the better question is not:
"How do we write the perfect prompt?"
It is:
"Where does the context live, who owns it, and how does the agent inherit it?"
That is the conversation that leads to reliable agentic QA.
And increasingly, it is the difference between AI that impresses in a demo and AI that performs reliably in production.
// Start testing //







