

A Failed Test Is Not a Bug Report
Short answer: Bug intelligence is the practice of turning a failed test into an evidence-backed explanation of what likely broke, why it broke, and where engineering should start. It combines runtime test evidence, historical pass/fail behavior, code changes, suspected commits, confidence signals, and bug context so QA teams can move faster from red test to real fix.
A sanity run fails.
One e-bikes test still passes. The product details test does not.
The report shows the price is missing, but that is only the symptom. Someone still has to answer the harder question: did the app break, did the test break, or did a recent code change quietly remove something the customer now needs?
Someone still has to answer the real questions. Did the product break, or did the test break? Did a recent commit cause it, or is this another flaky failure that will disappear on rerun? Which team owns it? What belongs in Jira? What can engineering trust?
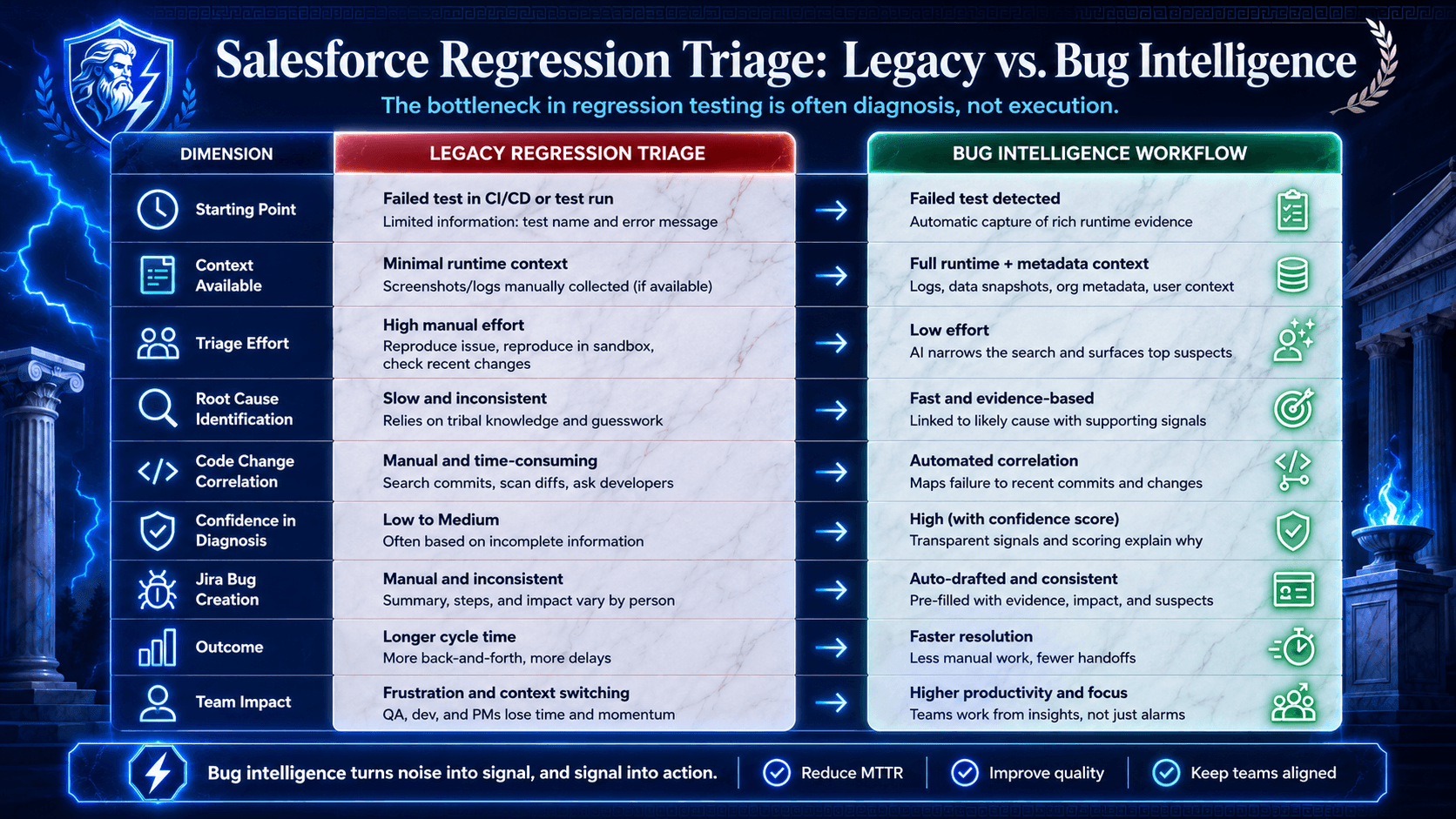
That gap between “test failed” and “we know why” is where QA teams lose time.
For Salesforce teams, that gap is especially painful because the business process usually matters more than the widget that broke. A permission change, a field-binding issue, a modified template, a changed record state, or a backend update can quietly break a workflow while the test report still stops at symptoms. Screenshot. Stack trace. Video. Maybe a trace. Useful evidence, yes. Not a diagnosis.
Red Is a Signal, Not an Explanation
Most regression tooling is good at detecting that something went wrong. Much less of it explains what changed.
That difference matters because modern release teams are not short on failed-test artifacts. Playwright’s Trace Viewer, for example, gives teams DOM snapshots, logs, network activity, console output, and step-by-step replay. Helpful. Selenium and CI platforms do the same in different forms. But more evidence is not the same thing as connected evidence.
A red test without change context still leaves humans doing the real triage work:
compare the failing run to the last passing run
inspect the likely commit window
decide whether the issue is flaky or real
figure out likely ownership
write a bug report developers will not bounce back for missing detail
That is why the stale belief to retire is this: a failed test is already a bug report.
It is not. It is an alert.

Why Teams Lose Time After the Failure
The pain is not theoretical.
Google wrote that about 1.5% of all its test runs showed flaky behavior, nearly 16% of tests had some level of flakiness, and roughly 84% of pass-to-fail transitions involved a flaky test. That is a brutal number because it means a red signal is often contaminated before triage even begins.
Microsoft makes the same point more bluntly in Azure DevOps documentation: flaky tests are a barrier to finding real problems because the failure often does not relate to the change being tested.
Atlassian recently shared that flaky-failure investigation can consume enormous engineering time, citing an internal estimate of 150,000 developer hours wasted annually in one major repository alone.
That maps cleanly to what practitioners say in the wild. In a recent r/devops thread, one team described an 800-test pipeline taking 45 minutes or more, with 5 to 10 random failures per run. Their engineers had started rerunning the pipeline and hoping for green because the alternative was treating QA as a permanent deployment bottleneck. That is not a tooling failure in the narrow sense. It is a trust failure.
And in Salesforce testing circles, people have been complaining for years about brittle Lightning UI automation and selector pain. The details vary, but the theme is familiar: the suite tells you something changed; it does not help enough with whether the change reflects business risk, UI volatility, or test maintenance debt.
The Real Problem Is Not Detection. It Is Diagnosis.
Here is the deeper issue: teams keep trying to solve regression pain by increasing test volume, adding more screenshots, or rerunning failures.
That helps at the edges. It does not solve the core problem.
If a team can detect failure quickly but still spends hours deciding whether the issue is a real regression, the testing system has automated execution but not understanding.
That is where bug intelligence becomes useful as a category idea.
Not “AI writes bugs for you.”
Not “the dashboard is smarter.”
Not “replace testers.”
The useful version is simpler: connect runtime symptoms to code change evidence so humans can make faster, better decisions.
A Concrete Salesforce Example
Take a simple Salesforce sanity suite for an e-bikes app.
One test validates that the Product Explorer shows a list of electric bikes and at least one visible title. Another validates product details when a bike is selected: product name, image, and price.
On a stable build, both pass.
Later, after a code change, the same suite runs again. One passes. One fails. The test definition itself has not changed.
That matters. It narrows the investigation.
A traditional report would still leave QA and engineering to do the legwork manually. Bug intelligence, done well, should go further:
identify the failing business symptom
correlate the failure to the likely code change window
pinpoint the affected file or template
distinguish a probable regression from a likely flaky result
package the evidence into a bug record someone can act on
In the demo transcript you shared, the useful detail was not that the suite turned red. It was that the failing behavior could be tied to a missing MSRP price field, linked to a removed UI binding, with suggested remediation and enough confidence for a human to approve the issue before it was raised in Jira.
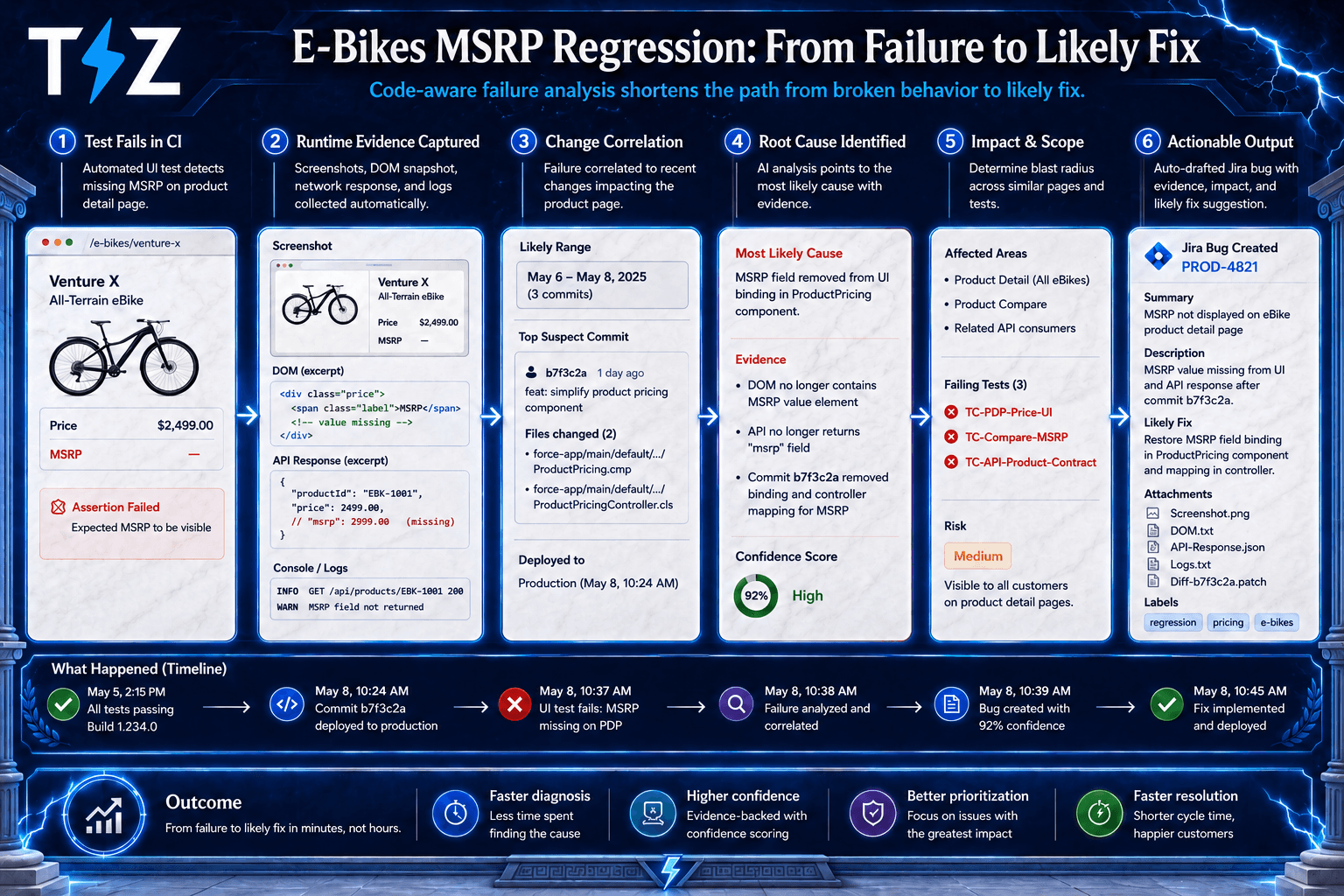
That is the shift. The value is not “test failed.” The value is “here is what likely changed, here is why the user-visible behavior broke, and here is where to start looking.”
Contrarian View: More Automation Volume Does Not Equal More Confidence
A lot of teams still behave as if confidence is a simple function of how many automated tests they have.
It is not.
A bigger suite with weak failure diagnosis often creates slower releases, more reruns, more ticket churn, and more arguments between QA and engineering. You do not get confidence from volume alone. You get confidence from trustworthy signals and fast explanation.
That is especially true in Salesforce environments, where the risk often lives in workflows, permissions, bindings, integrations, and user-specific business behavior. A green dashboard can still miss a broken approval path. A red dashboard can still overstate risk when the failure is just brittle UI coupling.
So the better question is not, “How do we automate more tests?”
It is, “How quickly can we move from failure to a trusted explanation?”
A Practical Framework for Real Regression Triage
When a test fails, the first job is not to file a bug. It is to decide whether the failure points to a real regression or just another noisy signal.
That decision gets easier when the team looks for five things in the same place.
Signal | What it helps you answer | Why it matters |
Runtime evidence | What exactly broke in the user flow? | Keeps the discussion tied to observed behavior instead of guesswork |
Last known good run | When did this flow last pass? | Helps narrow the change window |
Recent code changes | What changed between the passing run and the failing one? | Gives engineering a shorter path into the codebase |
Stability history | Has this test been reliable, or does it fail intermittently? | Helps separate likely regressions from flaky noise |
Likely owner | Which team, component, or developer should look first? | Cuts down back-and-forth and speeds up triage |
If those five signals are missing, the team usually falls back to the same routine: rerun the test, scan the logs, ask around, and write a thin ticket that engineering has to decode later.
If those five signals are present, the failure becomes much easier to handle. QA can say, with a straight face, “This flow was stable, it started failing after this change window, this is the behavior that broke, and this is where engineering should begin.” That is a much better starting point than a red status and a screenshot.
Where TestZeus Fits
TestZeus is interesting in this conversation not because “AI testing” is a fashionable phrase, but because it reflects a more useful direction for the category.
Testing is moving from script maintenance to agent supervision.
That means the important improvement is not just writing or running tests faster. It is giving QA teams better failure intelligence: connecting execution evidence, historical behavior, and code-aware context so a human reviewer can make a strong judgment quickly.
That is a better frame for agentic QA than the usual noise about replacing testers. The point is not to remove judgment. The point is to stop wasting it.
Practical Takeaways
If you run Salesforce regression suites today, three changes matter more than adding another layer of pass/fail reporting.
First, stop treating every red test as an already-formed bug. Make “what changed since the last passing run?” a default triage question.
Second, separate flaky classification from root-cause diagnosis. Those are related, but not identical. A rerun may tell you the signal is unstable. It does not tell you why.
Third, raise the bar for defect evidence. A useful bug report should include business symptom, failing test context, change window, suspected file or commit, and a reason someone should trust the diagnosis.
That is how regression testing becomes a release-confidence system instead of a screenshot archive.
FAQ
What is bug intelligence in software testing?
Bug intelligence is the process of turning a failed test into an evidence-backed explanation of what likely broke, why it broke, and where engineering should start, using runtime signals, historical behavior, and code-change context.
How is bug intelligence different from a normal test report?
A normal test report usually tells you what failed. Bug intelligence tries to explain why it failed, whether it looks like a real regression or flaky noise, and what code change or component is most likely involved.
Why is this especially useful in Salesforce testing?
Salesforce regressions often involve workflows, permissions, UI bindings, object relationships, and business-process logic. Those failures are expensive to debug manually because the visible symptom and the real cause are often far apart.
How do you tell a flaky test from a real regression?
You need history and context. Stable prior passes, a clear change window, reproducible runtime evidence, and correlation to a code change all increase confidence that the failure is a real regression rather than random noise.
What should a code-aware bug report include?
At minimum: the failed user flow, expected versus actual behavior, relevant logs or traces, historical test stability, suspected commit or code area, likely owner, and a clear explanation of why the diagnosis is credible.
Does bug intelligence replace QA engineers?
No. It should reduce manual investigation and low-value ticket assembly so QA can focus on judgment, risk, and release quality.
A red test should start a useful investigation, not a scavenger hunt. Teams that can connect failure signals to root cause faster will ship with more confidence than teams that simply accumulate more test runs.
If you are rethinking how Salesforce regression should work in an agentic QA world, this is the right place to start: not with more red dashboards, but with better answers.
// Start testing //







