

When we test traditional software, we usually start with a comforting assumption: if we understand the inputs, the rules, and the dependencies, we can build a reasonably complete test strategy.
We do not think that assumption holds for AI agents.
Agents are conversational, contextual, and probabilistic. A single-turn response can look correct and still hide deeper failures that only show up after repeated questioning, context shifts, tool invocation, or edge-case prompting. Salesforce’s own recent documentation reflects that shift: Agentforce Testing Center now supports multi-turn testing with conversation history, rather than only isolated prompt-response checks. (Developer)
That improvement matters. But from our standpoint as a team shaped by years of QA experience, it still leaves an important question:
Are we evaluating an agent, or are we deciding whether it is ready for production?
Why This Distinction Matters
We think many teams still blur two different jobs:
Evaluating agent behavior
Assuring production readiness
Those are related, but they are not the same.
Agentforce Testing Center is increasingly capable on the evaluation side. Salesforce documents support for expected topics, expected actions, expected outcomes, and quality metrics such as coherence, completeness, conciseness, latency, instruction adherence, and factuality. Tests can also include context variables and conversation history, and they can be defined and executed through Salesforce’s Testing API and DX workflows. (Developer)
That is useful. In many teams, it should be part of the stack.
But when we think about production risk, we care about a wider surface area: not just whether the agent answered, but whether it stayed grounded, used tools correctly, remained in scope, avoided disclosing sensitive information, and held up through longer, messier conversations.
That is where we see TestZeus Agent Harness as a different category of tool rather than just another testing UI. TestZeus positions Agentforce testing around multi-turn conversations, hallucination detection, data-quality validation, and end-to-end, cross-system workflows, instead of only agent-scoped evaluation. (TestZeus)
What Agentforce Testing Center Does Well
To be fair, Salesforce has added meaningful depth here.
From the public docs, Testing Center now supports:
Multi-turn testing using conversation history
Expected topic and action checks
Expected outcome comparison
Built-in quality metrics, including coherence, completeness, conciseness, latency, instruction adherence, and factuality
Test definition and execution through metadata, Connect API, and DX-based workflows (Developer)
If our immediate goal is to evaluate whether an Agentforce agent behaves as intended inside Salesforce’s own testing model, we would absolutely consider Testing Center a credible starting point. That is a stronger position than some older comparison narratives give it credit for. (Developer)
Where We Think the Gap Still Is
The gap, in our view, is not “single-turn versus multi-turn” anymore. Salesforce has already moved past that. (Developer)
The gap is broader:
Agentforce Testing Center helps evaluate the agent. Agent Harness is trying to answer whether the agent is safe and reliable enough to face real users.
That difference shows up in three places.
1. Evaluation Criteria vs. Operational Risk
Salesforce’s documented metrics are important, but they are still primarily evaluation-oriented: response quality, expected routing, expected actions, expected outcomes, and test-level latency. (Developer)
The Agent Harness framing is more operational. The product flow and messaging emphasize dimensions like consistency, data accuracy, tool usage, scope adherence, safety, groundedness, and information disclosure. Those are the kinds of risks we worry about when an agent is connected to enterprise data or customer-facing workflows. (TestZeus)
2. Agent-Scoped Testing vs. Broader Workflow Validation
The Salesforce sources we reviewed are centered on the agent’s behavior inside the Agentforce framework. That includes conversation handling, topic/action matching, and outcome quality. (Developer)
TestZeus, by contrast, publicly describes a broader testing surface: UI, API, integration, accessibility, security, regression, and visual validation, along with Agentforce-specific testing. We think that matters because production issues usually appear at the boundaries between systems, not just in the response text itself. (TestZeus)
3. Static Specifications vs. Adaptive Probing
Salesforce’s model is still rooted in defined tests, expected values, and structured evaluation criteria. That is a sensible design for repeatability. (Developer)
What we find more interesting in the Agent Harness approach is the idea of agentic, multi-turn probing: exploring pathways, running simulations, and grading the interaction across multiple dimensions rather than only validating whether a predefined expectation matched.
That is closer to how experienced testers think when the real goal is to uncover failure, not just confirm correctness. This part of the framing comes from our own Agent Harness workflow description and is directionally consistent with TestZeus’s public emphasis on multi-turn conversational testing and agentic validation. (TestZeus)
Comparison Table
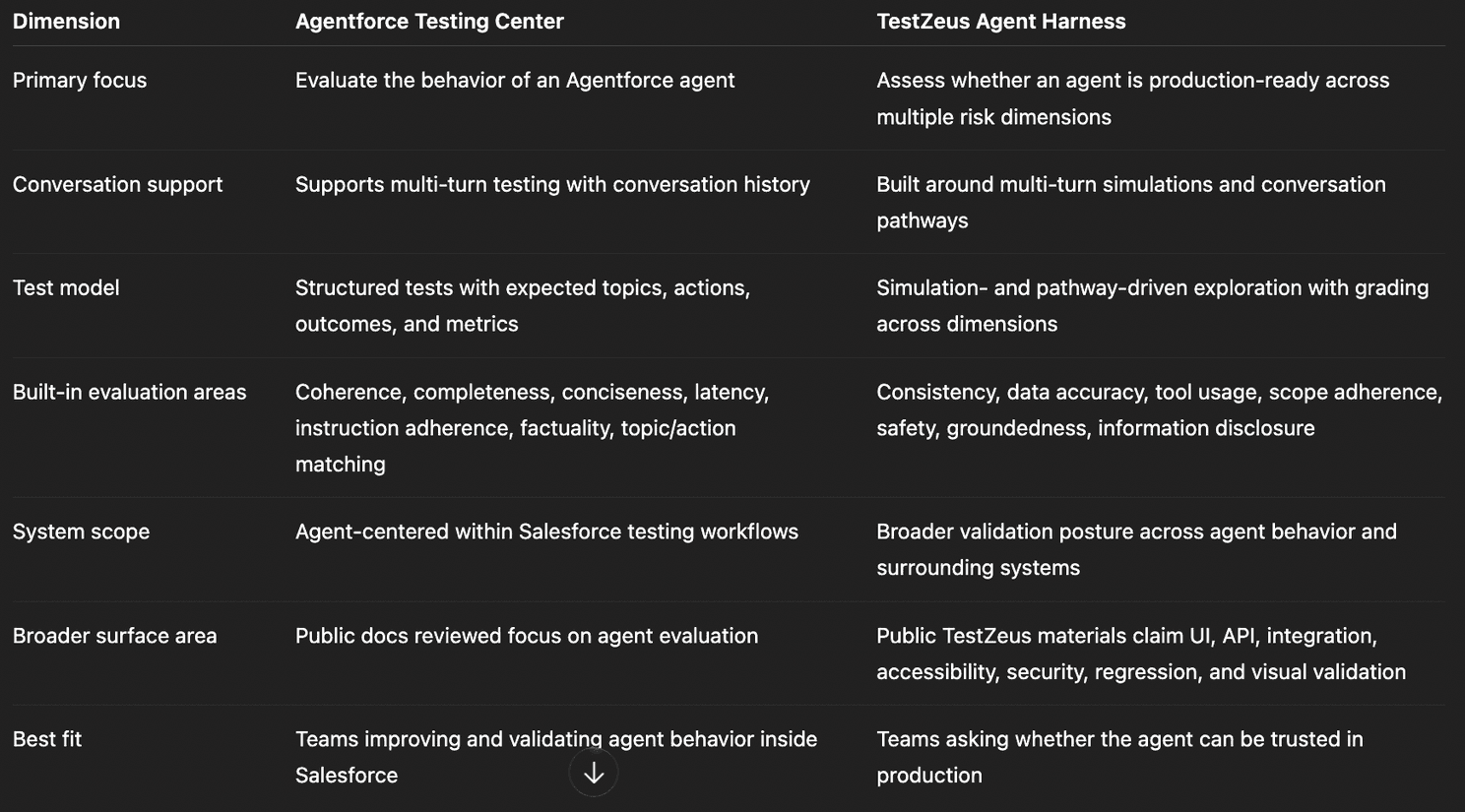
Important note: The Salesforce column should be grounded in official public documentation. The TestZeus column combines public TestZeus website claims with the Agent Harness positioning and workflow description.
The Practical Lens We Use
If we were advising an architect, CTO, CIO, or Head of QA, we would frame it this way:
Use Agentforce Testing Center when:
You want to validate agent behavior inside Salesforce
You need structured evaluation against expected actions, topics, and outcomes
You want built-in quality metrics and Salesforce-native execution workflows (Developer)
Use Agent Harness when:
You want to know whether the agent will hold up under real conversational pressure
You care about disclosure risk, groundedness, consistency, and tool correctness
You want a broader testing posture that extends beyond response scoring into production-readiness concerns (TestZeus)
For us, that is the cleanest distinction.
What We Would Not Claim
We would not claim that Agentforce Testing Center is “basic” or “single-turn only.” The current documentation does not support that. Salesforce has clearly improved the product, especially around multi-turn evaluation and built-in metrics. (Developer)
We also would not claim that production readiness can be reduced to one score or one chart. In practice, production readiness is a composite judgment across reliability, safety, data exposure, tool behavior, and failure handling.
What we would claim is narrower and, we think, more useful:
Agentforce Testing Center is a strong evaluation layer. Agent Harness is more compelling when the question becomes production assurance.
Final Thought
We have a bias here, and it comes from years of QA work: we do not trust systems that look polished too early. AI agents are exactly that kind of system.
They often sound right before they prove they are trustworthy. That is why we think the next phase of agent testing needs to move beyond response evaluation alone and closer to adversarial, multi-turn, production-minded assurance.
That is the gap we think Agent Harness is trying to fill.
Reference notes
Salesforce documentation supports the claims here about multi-turn testing with conversation history, expected topics/actions/outcomes, and built-in metrics such as coherence, completeness, conciseness, latency, instruction adherence, and factuality. (Developer)
TestZeus public materials support the claims here about multi-turn conversational testing, hallucination detection, data-quality validation, cross-system workflows, and broader testing coverage claims across UI, API, accessibility, security, regression, and visual validation. (TestZeus)
// Start testing //







